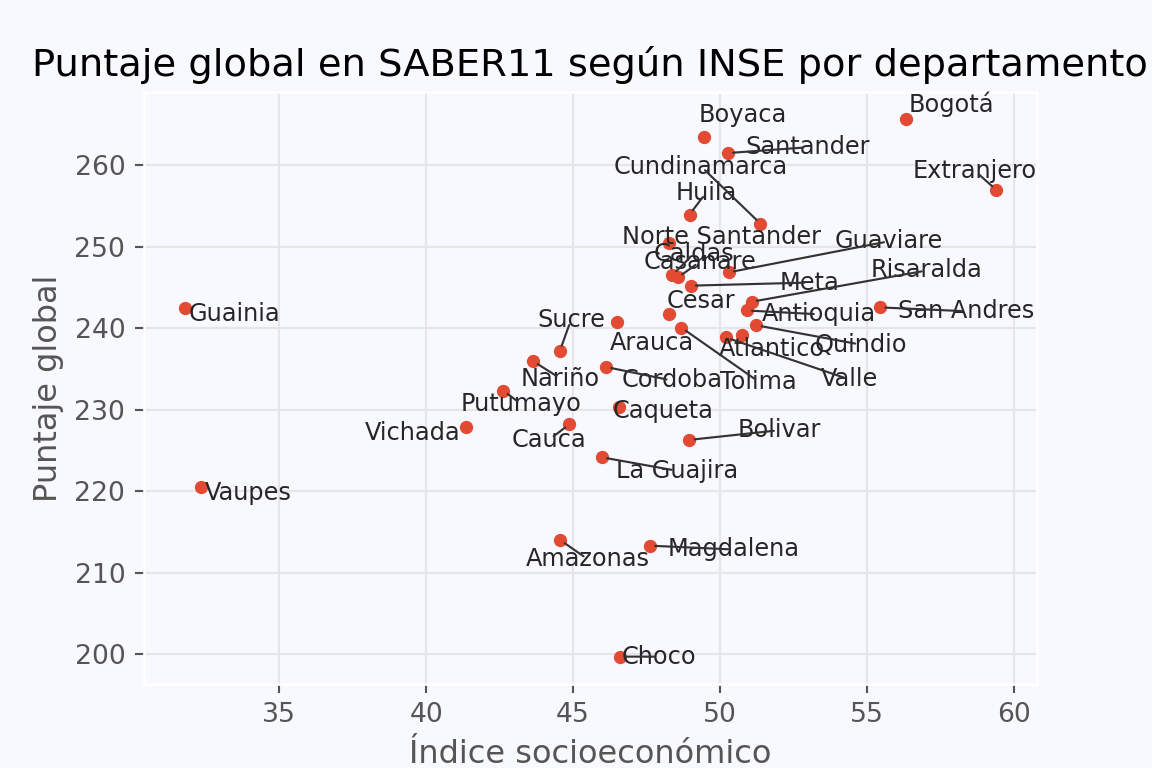
13.4 Ajuste de etiquetas
El módulo adjustText que ajusta la etiqueta para tratar de evitar sobrelapamientos:
departamentos = (saber
.groupby('estu_depto_reside', dropna=True)[['estu_inse_individual',
'punt_global']]
.mean()
.reset_index())
departamentos['estu_depto_reside'] = departamentos['estu_depto_reside'].str.title()
x = departamentos['estu_inse_individual'].to_numpy()
y = departamentos['punt_global'].to_numpy()
labels = departamentos['estu_depto_reside'].astype(str).to_numpy()
fig, ax = plt.subplots(figsize=(6,4))
_ = ax.scatter(x, y, s=20)
_ = ax.grid(True, color='0.9')
_ = ax.set_xlabel('Índice socioeconómico')
_ = ax.set_ylabel('Puntaje global')
_ = ax.set_title('Puntaje global en SABER11 según INSE por departamento')
# Añadir las etiquetas asocxiadas a cada punto
texts = [ax.text(xi, yi, lab,
ha='left', va='center', fontsize=9,
color = '0.15')
for xi, yi, lab in zip (x, y, labels)]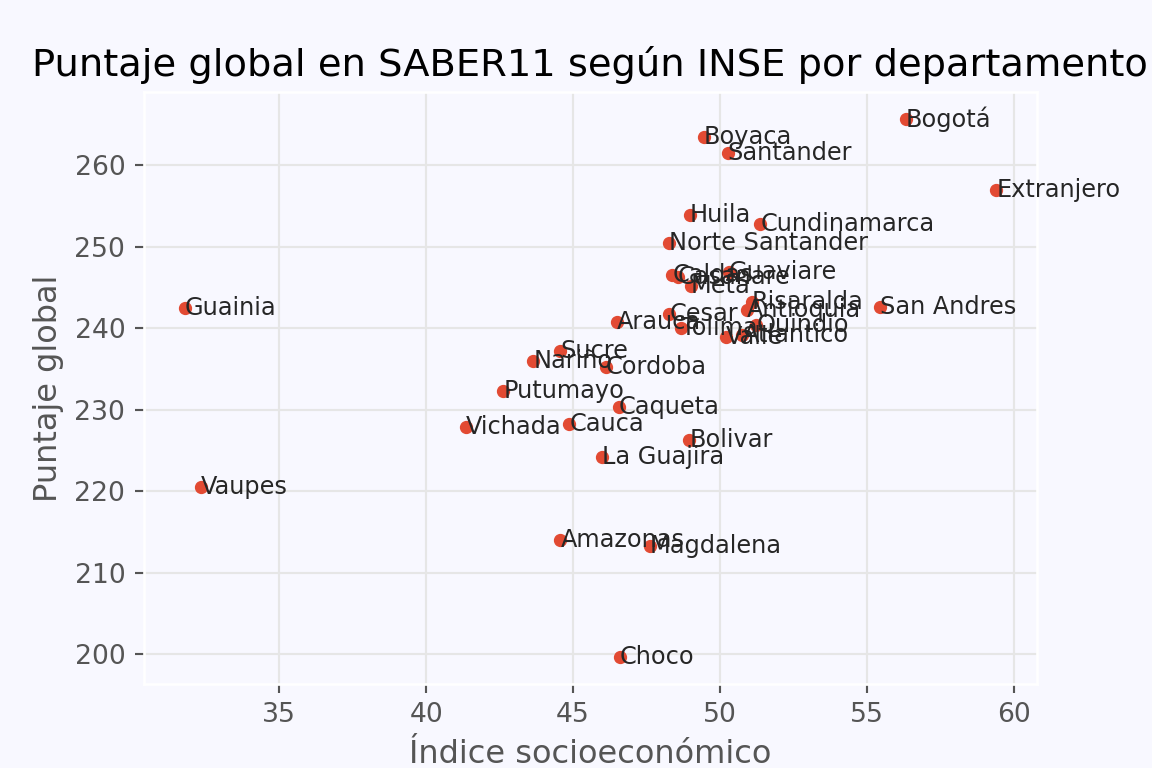
Compárese. Mejora en algo.
departamentos = (saber
.groupby('estu_depto_reside', dropna=True)[['estu_inse_individual',
'punt_global']]
.mean()
.reset_index())
departamentos['estu_depto_reside'] = departamentos['estu_depto_reside'].str.title()
x = departamentos['estu_inse_individual'].to_numpy()
y = departamentos['punt_global'].to_numpy()
labels = departamentos['estu_depto_reside'].astype(str).to_numpy()
fig, ax = plt.subplots(figsize=(6,4))
_ = ax.scatter(x, y, s=20)
_ = ax.grid(True, color='0.9')
_ = ax.set_xlabel('Índice socioeconómico')
_ = ax.set_ylabel('Puntaje global')
_ = ax.set_title('Puntaje global en SABER11 según INSE por departamento')
# Crear etiquetas en sus posiciones iniciales
texts = [ax.text(xi, yi, lab,
ha='left', va='center', fontsize=9,
color = '0.15')
for xi, yi, lab in zip (x, y, labels)]
adjust_text(texts,
x=x, y=y, ax = ax,
only_move={'points': 'xy', 'text': 'xy'},
expand_points=(1.15, 1.10),
expand_text=(1.05, 1.10),
arrowprops=dict(arrowstyle='-', color='0.2', lw=0.8))