33.5 Imputación de datos
Un aspecto donde hay investigación actualmente es cómo evaluar los diferentes métodos de imputación de datos. La visualización es una de las formas en que se comprueba.
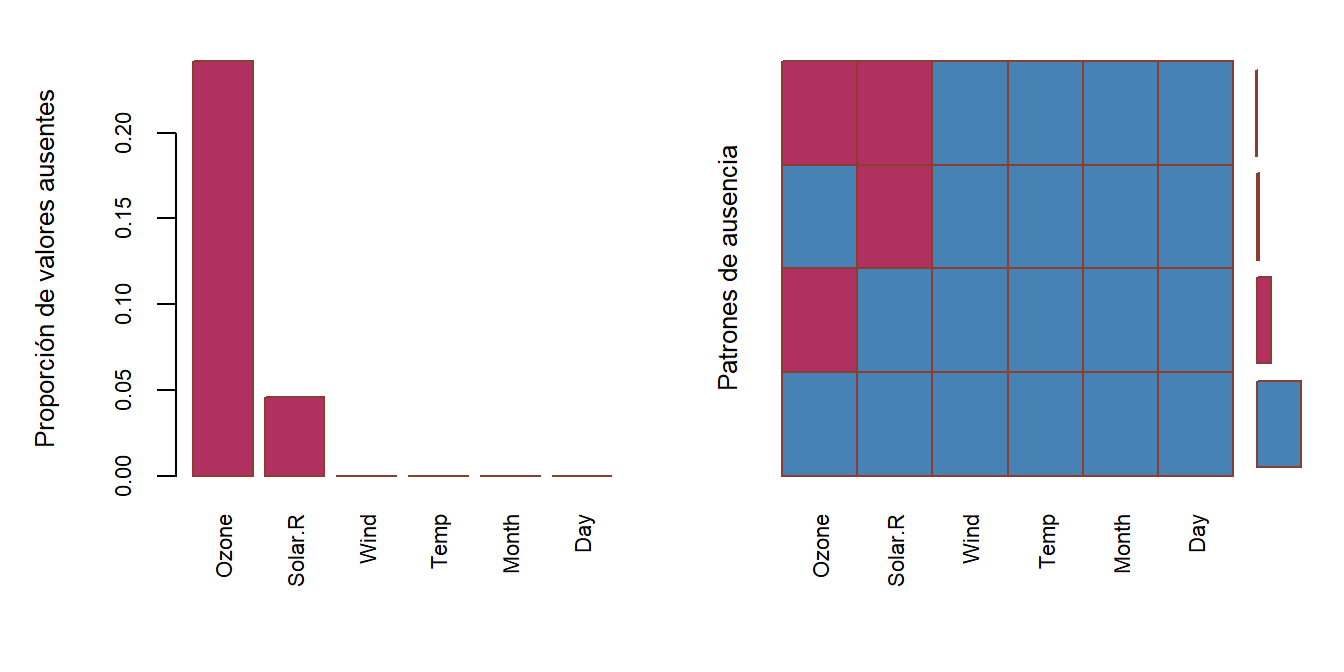
Los patrones de ausencia son todas las posibles combinaciones de valores faltantes y no faltantes. En la visualización hay 4 patrones de ausencia, ya que incluye patrón de ausencia = 0. En general, hay \(2^n\) patrones de ausencia, donde n es igual al número de variables que tienen uno o más valores ausentes.
Otra opción son los Cleveland plots:
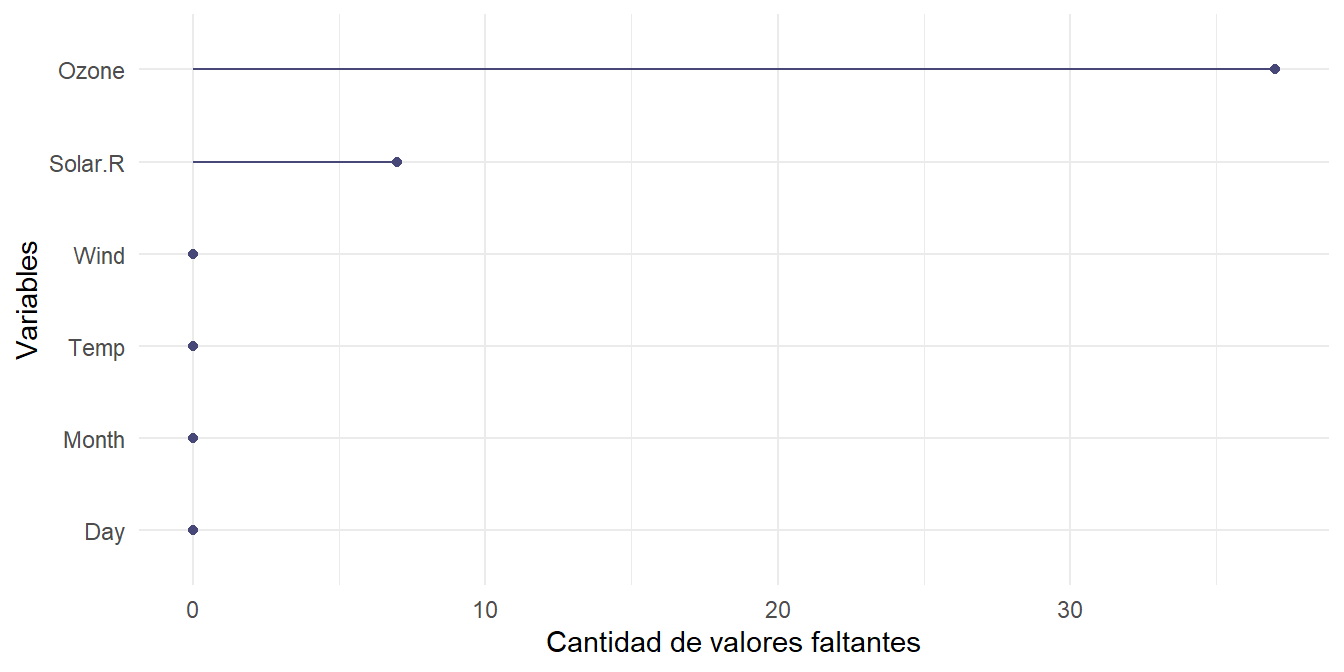
Se aplica una prueba de Little:
## # A tibble: 1 × 4
## statistic df p.value missing.patterns
## <dbl> <dbl> <dbl> <int>
## 1 35.1 14 0.00142 4La prueba de Little evalúa si los valores que faltan están “desproporcionadamente” asociados a ciertos rangos de las variables observadas, lo cual se detecta comprobando si las medias de cada variable difieren entre los distintos patrones de ausencia. Es decir, prueba si los datos ausentes en el conjunto de datos se distribuyen de forma completamente al azar (MCAR - Missing Completely At Random)27.
En presencia de colas pesadas o asimetrías acusadas se recomienda realizar pruebas de bootstrap.
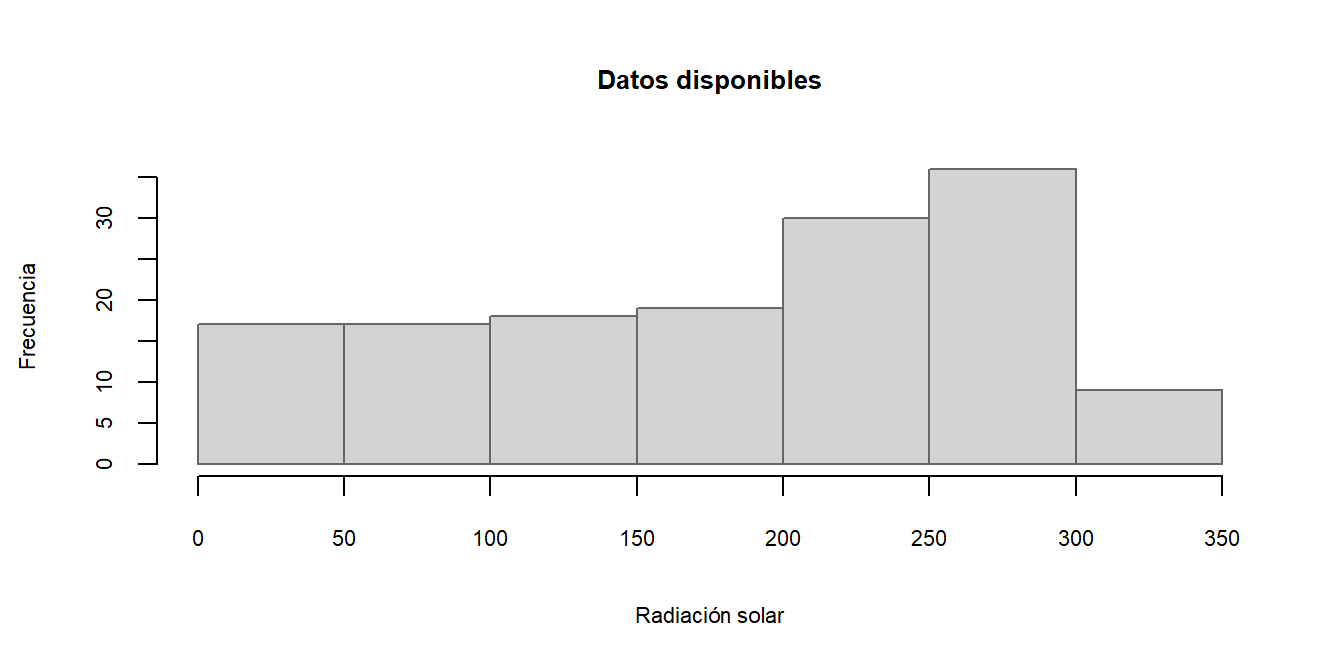
Un gráfico de columna (spline plot) es un tipo específico de gráfico de mosaico para solo dos variables: El ancho de cada barra apilada es proporcional al total de toda la categoría. Verticalmente presenta el porcentaje de valores ausentes. Como el eje horizontal presenta una variable continua, se categorizó creando rangos de valores por la regla de Sturges.
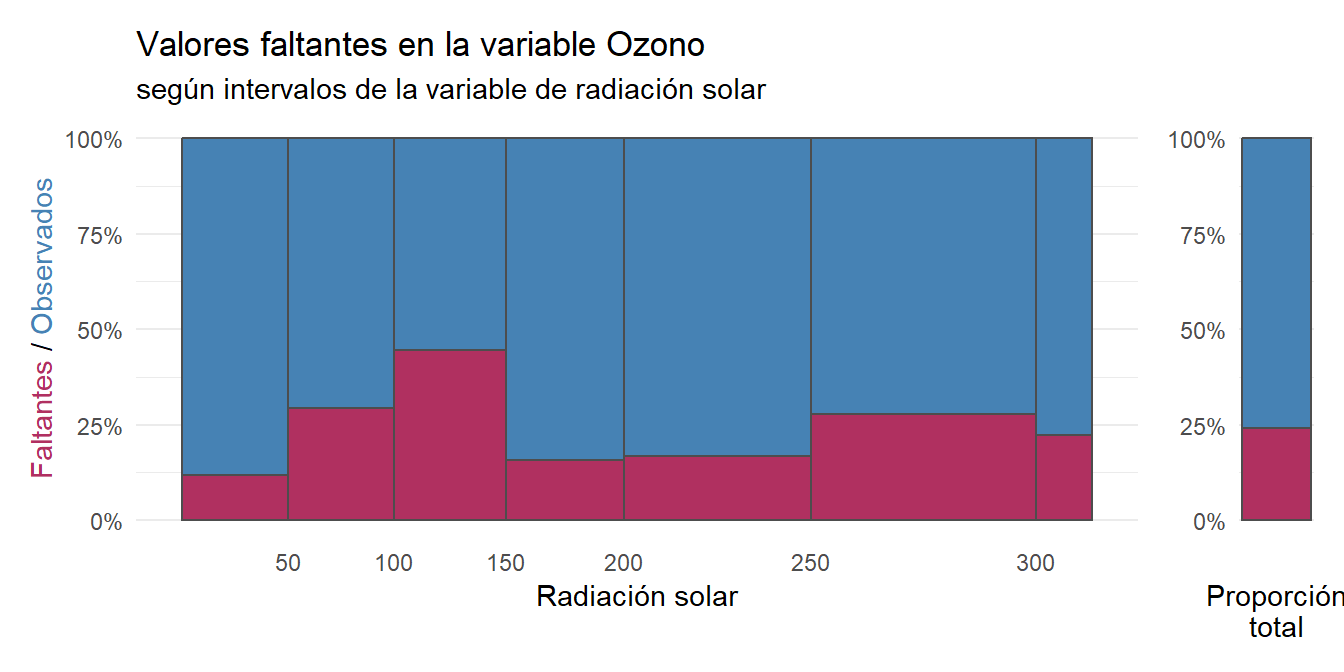
Se procede a imputar una única imputación28 según la media.
##
## iter imp variable
## 1 1 Ozone Solar.R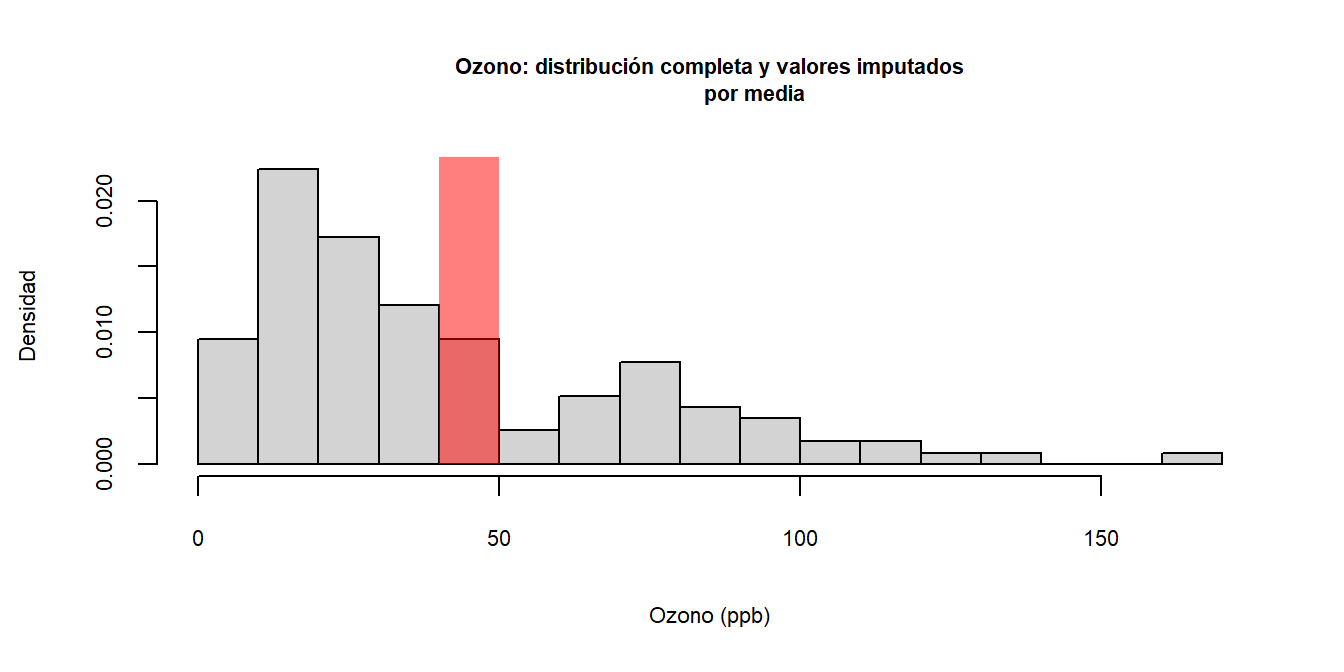
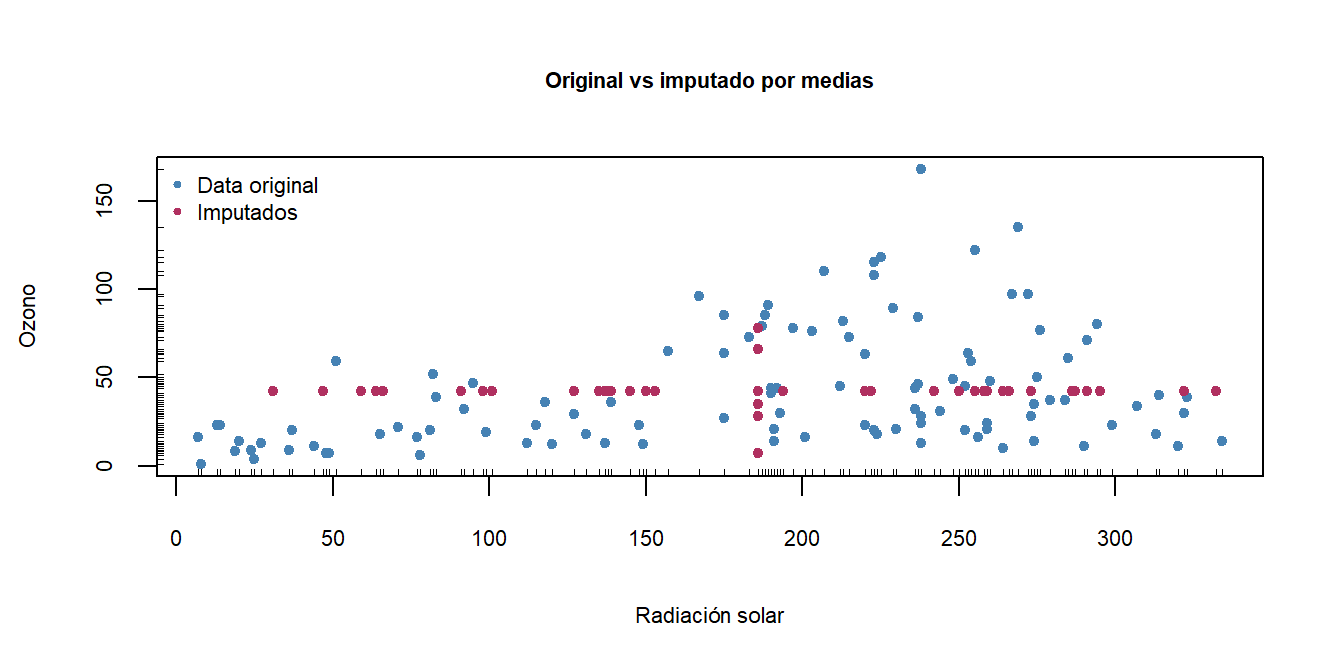
Se presenta a continuación el resultado según otros métodos de imputación.
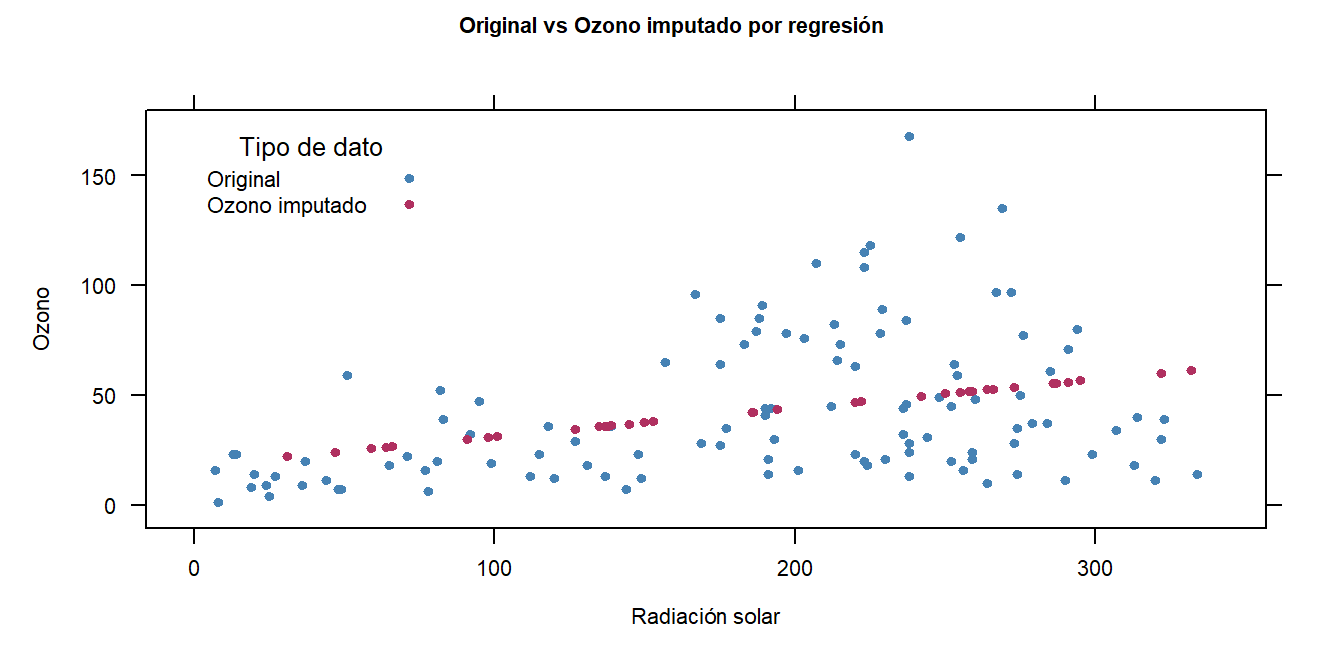
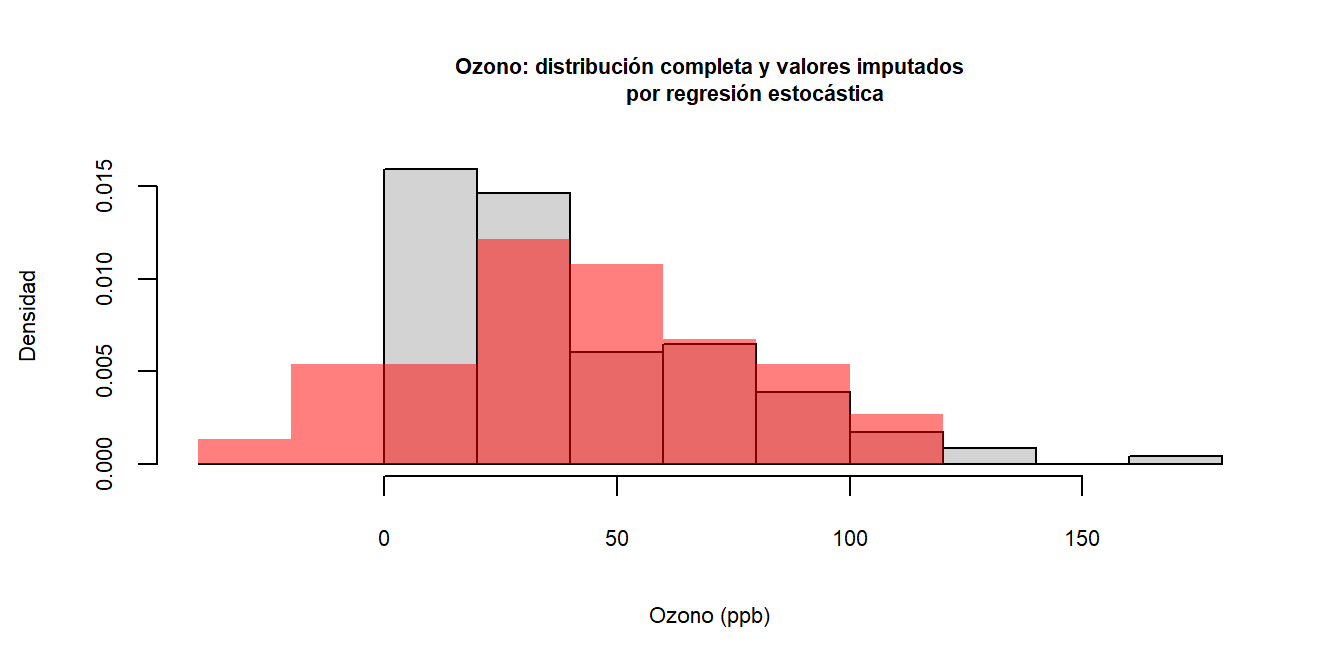
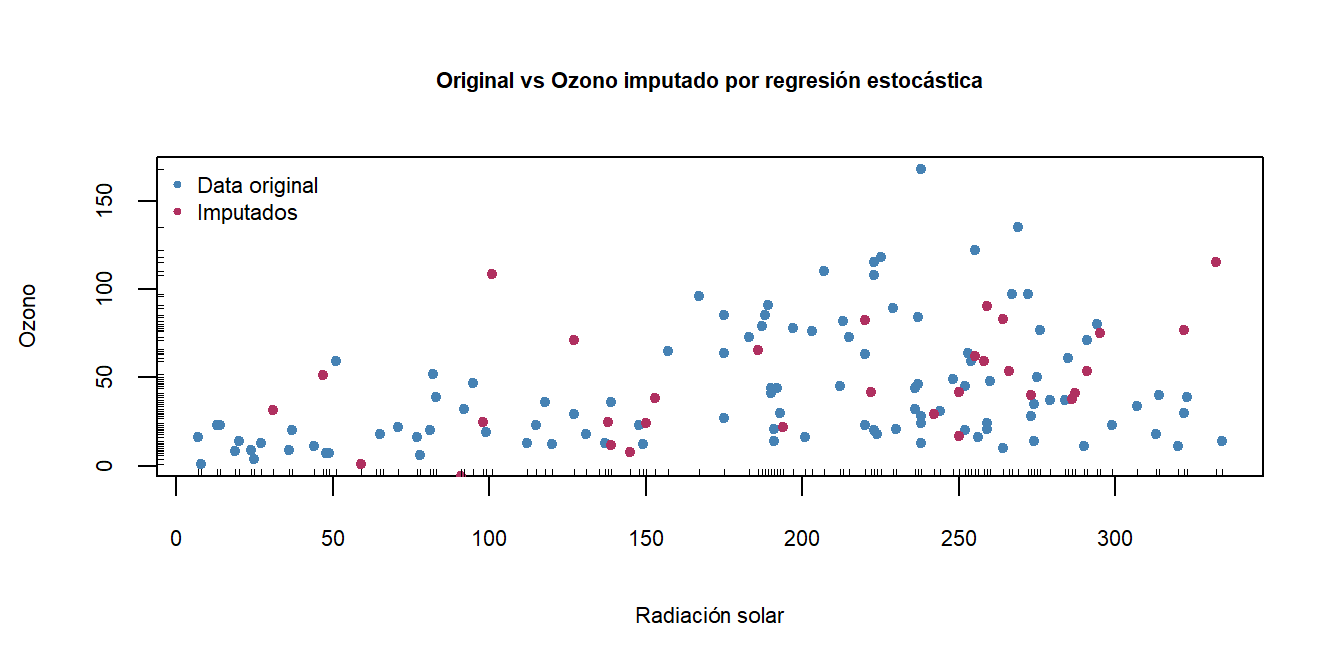
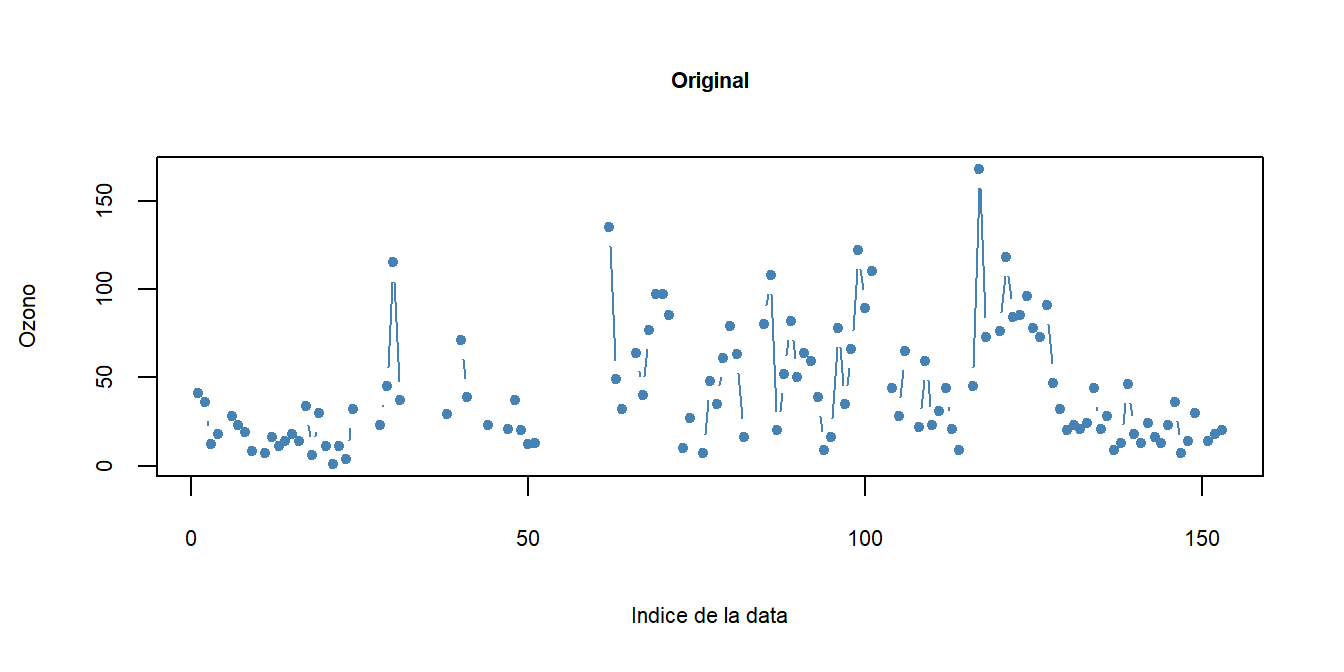
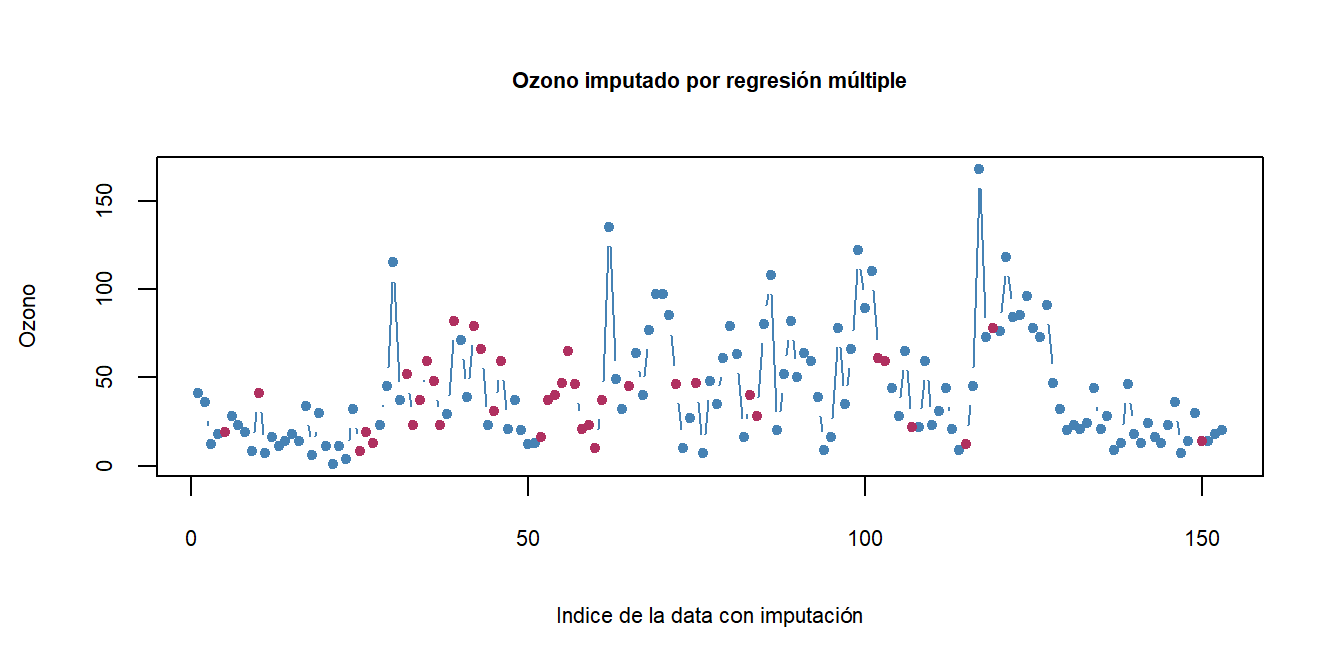
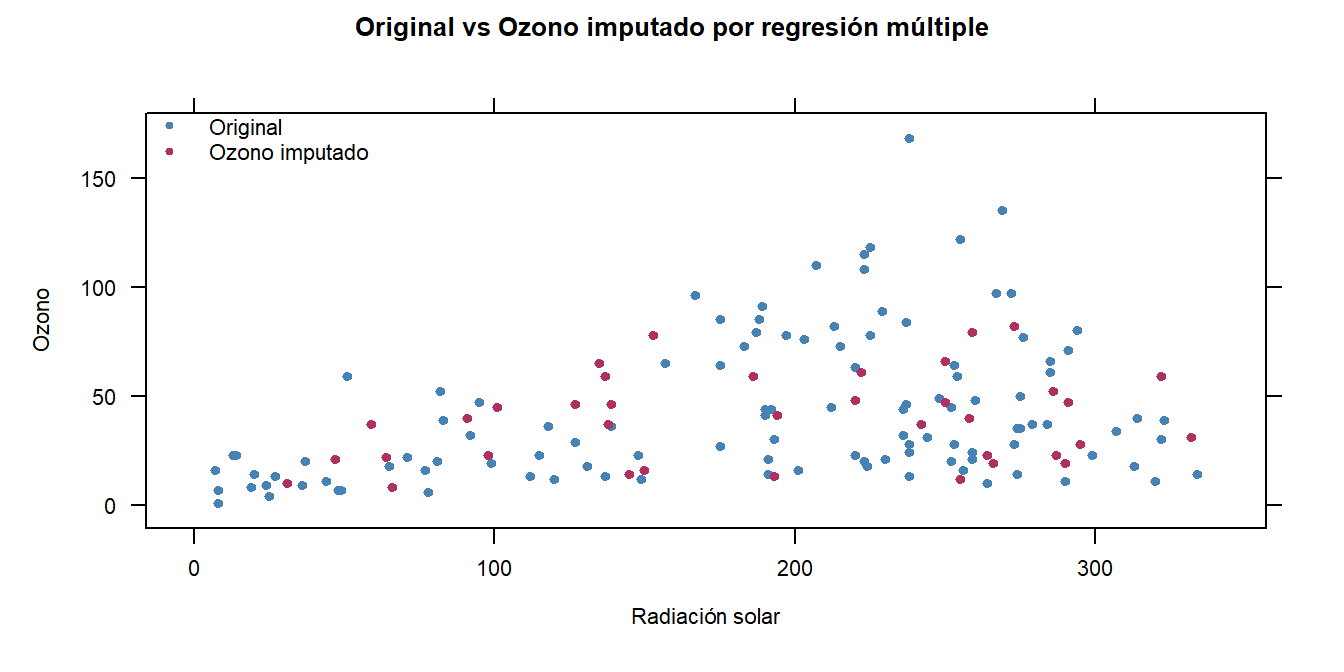
La visualización de los diagramas de dispersión permite observar cuál método se ajusta mejor a la estructura inherente de los datos, generando datos con buena variabilidad pero sin datos extraños.
Uno de los supuestos de la prueba de Little es que los datos completos (las observaciones sin NA) se distribuyen según una normal multivariante. La prueba es razonablemente robusta frente a leves violaciones del supuesto de normalidad (con comportamiento conservador), pero pierde fiabilidad cuando las desviaciones son muy fuertes, especialmente en presencia de colas pesadas o asimetrías acusadas.
Para cada patrón de ausencia \(j\) se calcula la media muestral \(\boldsymbol{\bar x}_j\) de cada variable observada en ese patrón. Se estima tambien la matriz de covarianza conjunta \(\boldsymbol{S}\) sobre todos los datos completos (o usando métodos de máxima verosimilitud asumiendo una distribución normal multivariante).
Bajo la hipótesis nula (MCAR), todas las medias de patrón \(\boldsymbol{\bar x}_j\) deberían coincidir con la media global \(\boldsymbol{\bar x}\) (pues la ausencia no depende de la magnitud de las variables).
El estadístico de prueba es:
\[\chi^2 \;=\;\sum_{j=1}^{J} n_j\,(\boldsymbol{\bar x}_j - \boldsymbol{\bar x})^\top \,\boldsymbol{S}^{-1}\,(\boldsymbol{\bar x}_j - \boldsymbol{\bar x})\,,\]
donde \(n_j\) es el número de casos en el patrón \(j\). Matemáticamente es un contraste de medias multivariado, que bajo MCAR sigue aproximadamente una \(\chi^2\) con grados de libertad acordes al número de patrones y variables: \(df = (\text{número de patrones de ausencia} − 1)(\text{número de variables observadas})\)
Si la probabilidad de que los datos apoyen la hipótesis nula es muy pequeña (menor al nivel de significancia especificado previamente), se rechaza MCAR, concluyendo que la ausencia depende de los valores de las variables.
Aunque a alto nivel se dice que “compara medias entre patrones de ausencia”, internamente tiene en cuenta la estructura de covarianzas y el tamaño de cada patrón para construir un estadístico de chi-cuadrado multivariado.↩︎
Lo usual son múltiples imputaciones.↩︎