3.1 La abstracción de datos
La abstracción de datos para la visualización tiene un vocabulario propio, diferente al de las ciencias de la computación y al de la estadística. Similar, pero propio, y posiblemente más rico. Se toma de Munzner (Munzner 2014).
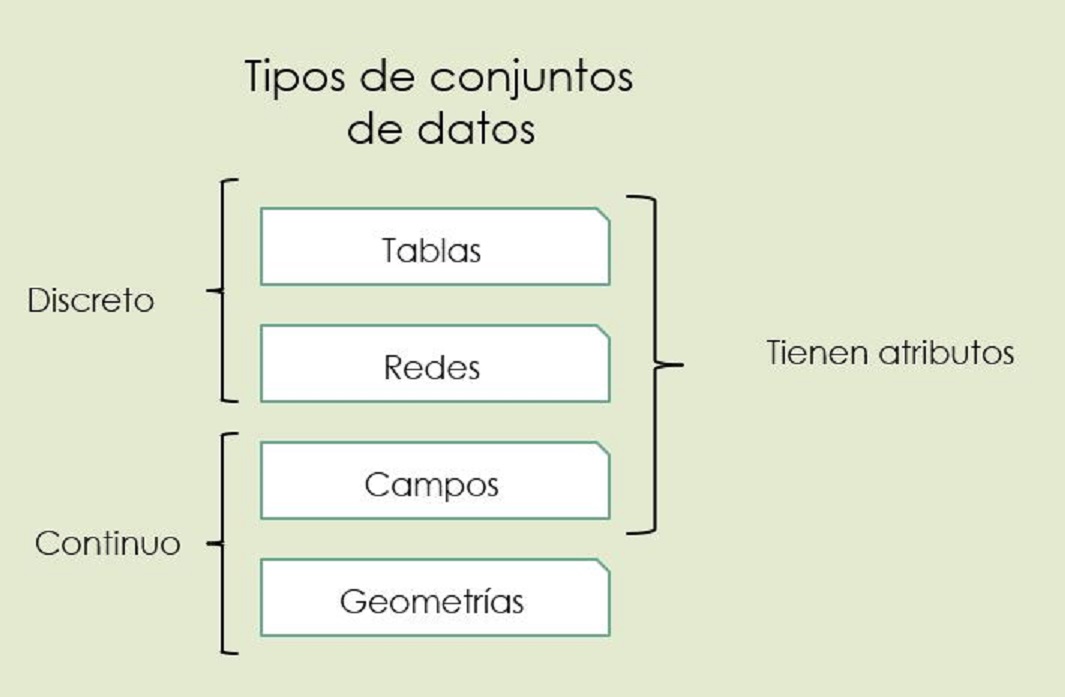
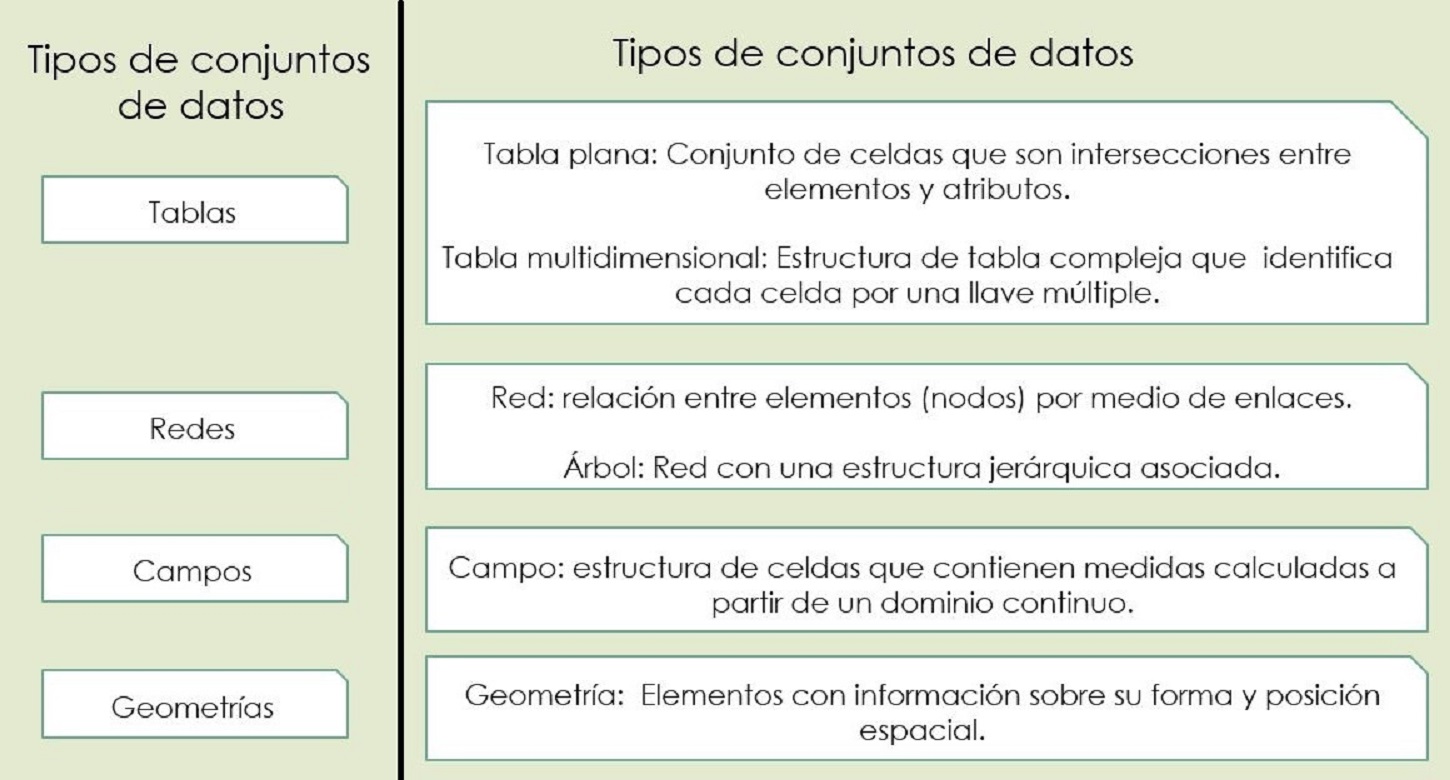
Hay cuatro tipos básicos de conjuntos de datos a visualizar: tablas, redes, campos y geometrías.
Hay otros tipos de colecciones de objetos a representar, que incluyen a conjuntos, listas y conglomerados.
Pueden estar disponibles de manera estática o en la forma de un flujo.
Si se tiene toda la estructura de datos en un momento dado, se trata de un archivo estático.
Si la estructura de datos es dinámica en tiempo real o en periodos cortos, ya sea que se añaden nuevos datos, se borran algunos datos o se cambian sus valores, se denomina flujo de datos.
Los conjuntos de datos están conformados por combinaciones de cinco tipos de datos: elementos, enlaces, posiciones, retículas y atributos.
Un elemento es una entidad individual tal como la fila de una tabla o un nodo de una red.
Un enlace es una relación entre dos o más elementos, usualmente, de una red.
Una posición es un dato espacial, ya sea en un espacio 2D o 3D.
Una retícula se compone de celdas y especifica una estrategia para muestrear datos de tipo continuo dentro de una relación topológica y geométrica entre sus correspondientes celdas.
Un atributo es una propiedad que puede ser medida, observada o registrada. Los atributos de los datos se clasifican en categóricos y ordenados. Estos últimos se pueden subclasificar en ordinales y cuantitativos.
Diferenciemos conceptos. En la disciplina de la visualización la semántica es el significado de los datos en el mundo real. Los datos per sé carecen de significado. Una vez ubicados en su respectivo contexto se suelen denominar información. Cuando se comprende y se utiliza para la toma de decisiones se convierte en conocimiento.
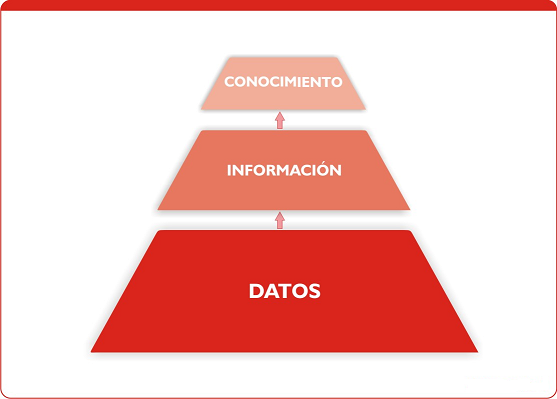
El tipo del dato es su interpretación estructural o matemática.
A nivel de un conjunto de datos, el tipo es definir si se trata de un árbol, o un campo.
A nivel de datos, el tipo es especificar si es un elemento, un enlace o un atributo.
Los conceptos que a continuación se enumeran son, valga la redundancia, conceptuales. No se confundan con representaciones concretas que conocemos.
Una tabla plana es un conjunto de datos que se suele definir que consta de filas y columnas o casos y variables, pero en visualización se dice que tiene elementos y atributos. Una celda de una tabla es la intersección entre un elemento y un atributo, y tiene un valor asociado a esa intersección.
Una tabla multidimensional es una estructura más compleja que una tabla plana y por tanto se identifica una celda por medio de una llave múltiple.
Las redes representan relaciones entre elementos. Los elementos se denominan nodos y las relaciones enlaces. Tanto los nodos como los enlaces pueden tener asociados atributos.
Figura 3.1: Ejemplo de red expresada en una visualización
Una red con una estructura jerárquica asociada se denomina árbol. Otra característica distintiva del árbol es que no tiene ciclos. Cada nodo hijo tiene un único nodo padre.
Las tablas y las redes representan entidades en el dominio de lo discreto, de lo contable.
Campos
Los campos son estructuras de datos asociados a celdas que contienen medidas calculadas a partir de un dominio continuo, de lo incontable. La continuidad implica que entre cualquier par de valores siempre hay valores intermedios. Por dicha razón cabe realizar cálculos de agregación si se quiere resumir información que represente ese continuo, o realizar un cálculo de interpolación para representar dicha continuidad. La agregación y la interpolación permiten realizar un zoom del campo. Si se tiene una estructura de datos de algún campo, implícitamente se ha obtenido una muestra.
Es usual el uso de campos en los temas donde interesa la forma (topología) del objeto de estudio, por tanto, se tienen campos espaciales.
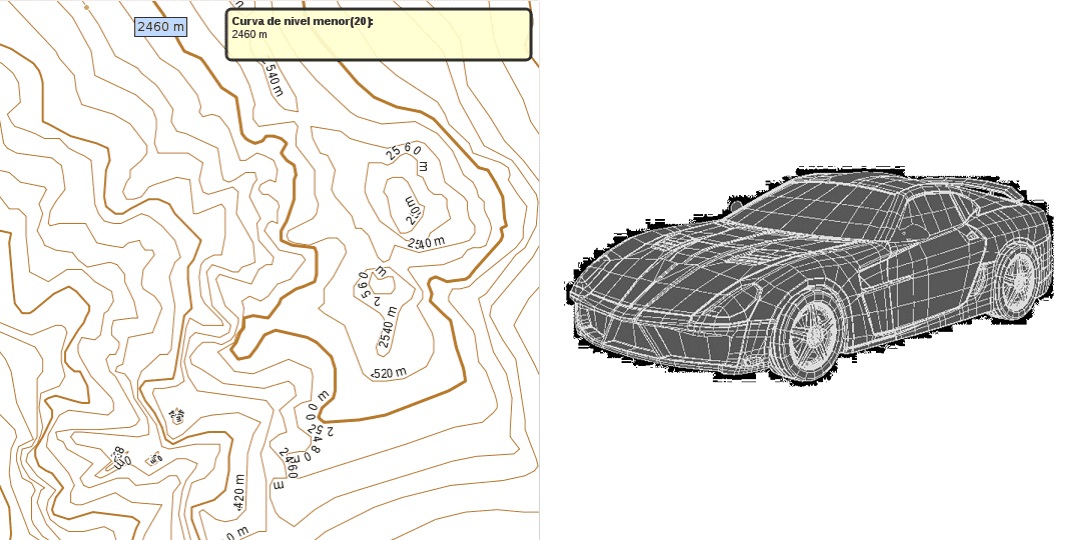
Figura 3.2: Ejemplos de campos espaciales expresados en visualizaciones
Fuente: https://alternativaslibres.org/es/hires_contours.php y https://free3d.com/es/modelo-3d/car-prototype-8427.html
El campo espacial de la izquierda del ejemplo presentado en la Figura presenta los puntos del terreno que tienen la misma altura. Entre más juntas estén las líneas, mayor pendiente tiene el terreno representado.
Un campo en el que se ha guardado la información muestreada a espacios regulares conforma una retícula uniforme.
Una retícula rectilínea implica que el espaciado entre muestras no es uniforme. Se utiliza cuando hay mayor complejidad en unos espacios y menor en otros.
Una retícula estructurada permite formas curvilíneas, lo que conlleva la especificación geométrica de cada celda.
Una retícula no-estructurada permite total flexibilidad, pero requiere especificar cómo se conectan unas celdas con otras.

Figura 3.3: Ejemplo de retículas
Fuente: https://www.nas.nasa.gov/Software/FAST/RND-93-010.walatka-clucas/htmldocs/chp_16.surferu.html
Obsérvese que los campos implican una gran cantidad de información por celda.
Geometrías
Una geometría especifica información sobre la forma de los elementos que la componen junto con la posición espacial. Suelen ser datos espaciales. Puede tratarse de puntos, curvas, superficies o volúmenes. No necesariamente tienen atributos asociados, lo que sí ocurre en las tablas, redes y campos.
Para acarar ambos conceptos, sea un ejemplo: una placa metálica semicircular.
Desde el punto de vista conceptual, la temperatura sobre la placa es un campo escalar: a cada punto del dominio 2D se le asigna un único valor (la temperatura) \(T(x,y)\).
Las fechas representan el campo escalar de temperatura.
Pero también, se puede representar la temperatura como un mapa de calor y las isotermas (curvas de nivel). Dicha representación es geométrica.
Las curvas de nivel o isotermas son geometrías derivadas del campo escalar: para un valor fijo c, la curva \(T(x,y)=c\)


Resumen
Otros conjuntos de datos
Los conjuntos son un grupo no ordenado de elementos.
Cuando los conjuntos tienen un orden se denominan lista.
Si la agrupación está basada en la similaridad de algún atributo, es un conglomerado.
Tipos de atributos
Atributos categóricos son aquellos de caracter nominal, es decir, que obedecen a una denominación. Sólo se puede distinguir si pertenecen a una categoría u otra: tragedia vs. comedia, real frente a ficticia, gótica vs. ciber-punk.
Atributos ordenados son aquellos que ademas de tener una denominación tienen de manera natural un orden: posición en un ranking establecido, tamaño.
Los atributos ordenados pueden ser de caracter cuantitativo, en cuyo caso hay un concepto numérico o matemático que los ordena, o de caracter puramente ordinal, como la posición basado en características.
La dirección de los atributos ordenados puede ser: secuencial, divergente o cíclica.
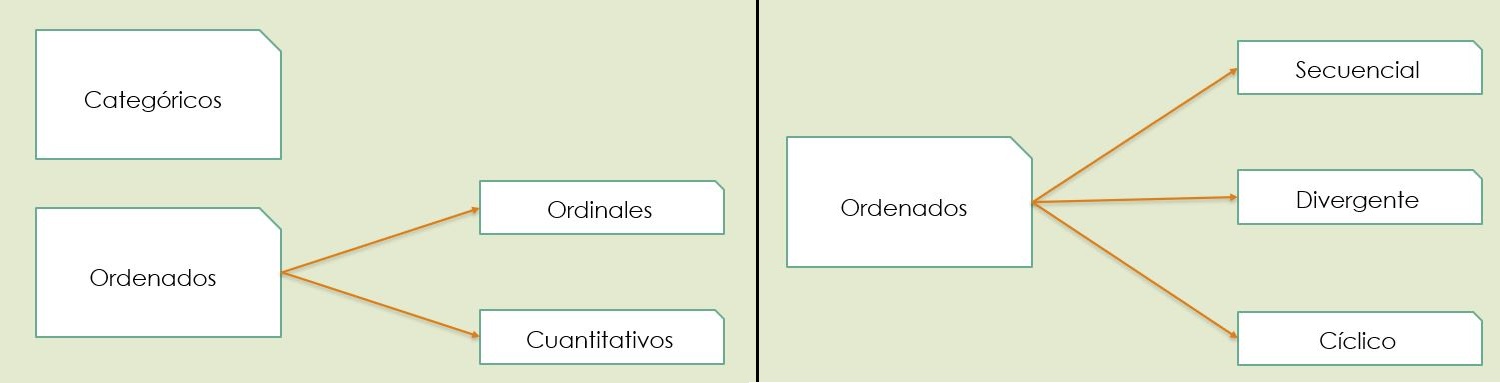
La dirección de los atributos es secuencial si tiene un valor mínimo y un máximo, divergente si de un punto inicial parten dos secuencias en direcciones opuestas, y cíclicos si al llegar a un punto regresa al punto inicial y continúa la secuencia. La siguiente figura presenta paletas de colores asociadas a cada tipo de datos ordenados:

Figura 3.4: Paletas de color para los tipos de datos ordenados: secuencial, divergente y cíclico
Estructuras jerárquicas
Un conjunto de diferentes atributos pueden tener una estructura jerárquica. Los días se agregan en semanas, o en quincenas, éstas en meses, éstos en años, éstos en lustros o en décadas, etc… Lo mismo ocurre con otro tipo de atributos, los municipios en regiones, las regiones en departamentos, éstos en naciones, …