33.4 Visualizaciones usadas para el análisis
La visualización no sólo se utiliza en el proceso de exploración de los datos o en la presentación de resultados. También se puede usar en la fase de inferencia (Buja et al. 2009). Para explicarlo, presento las ideas de Buja et. al. respecto a realizar diagnóstico de modelos a partir de visualizaciones, es decir, a partir de métodos cualitativos.
Los autores hacen referencia a la común escena de película policíaca en la que solicitan a los testigos identificar al criminal de entre una hilera de supuestos sospechosos. Em medio de los falsos sospechosos está el verdadero. Todos tienen aspecto de criminales (o todos parecen buenos ciudadanos). El verdadero sospechoso está entre todos los demás.
Si son n sospechosos y sólo uno es auténtico, la probabilidad de hacerlo al azar es de 1/n. Pero si se trata de k testigos, la probabilidad de que todos ellos identifiquen al sospechoso auténtico disminuye drásticamente.
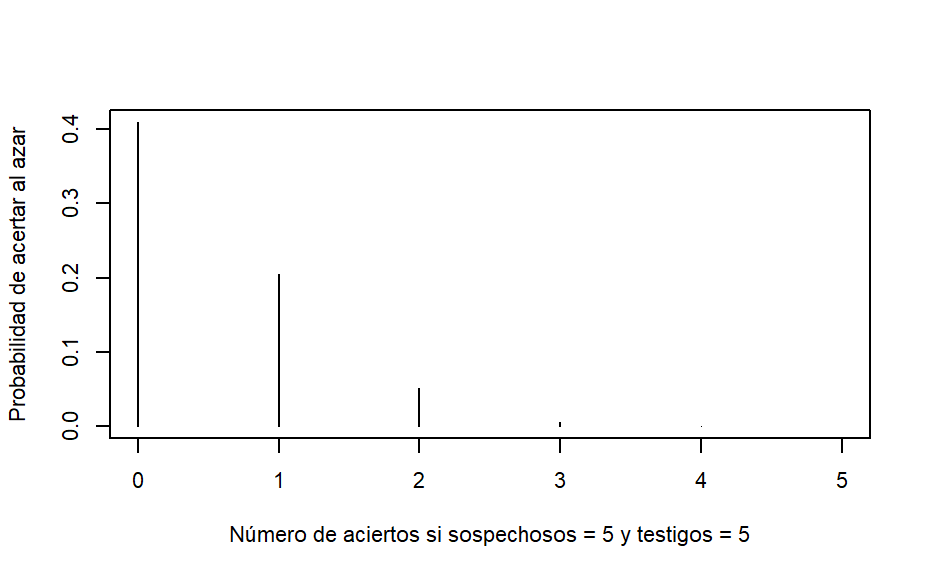
Se calcula como la probabilidad binomial de identificar k veces (número de testigos) con éxito al verdadero sospechoso de entre n sospechosos, con una probabilidad de 1/n.
La aplicación a la inferencia en el diagnóstico de modelos a partir de visualizaciones es mediante un protocolo sencillo: Se generan n - 1 visualizaciones bajo la hipótesis nula y se inserta al azar la visualización de los datos reales en medio. Se solicita a k analistas, que no han sido expuestos previamente a los datos, que identifiquen la visualización que se diferencia de las demás. Se verifican los aciertos frente a la probabilidad binomial y si \((\sum{aciertos})/k\) es significativamente mayor a lo teórico, se rechaza la hipótesis nula.
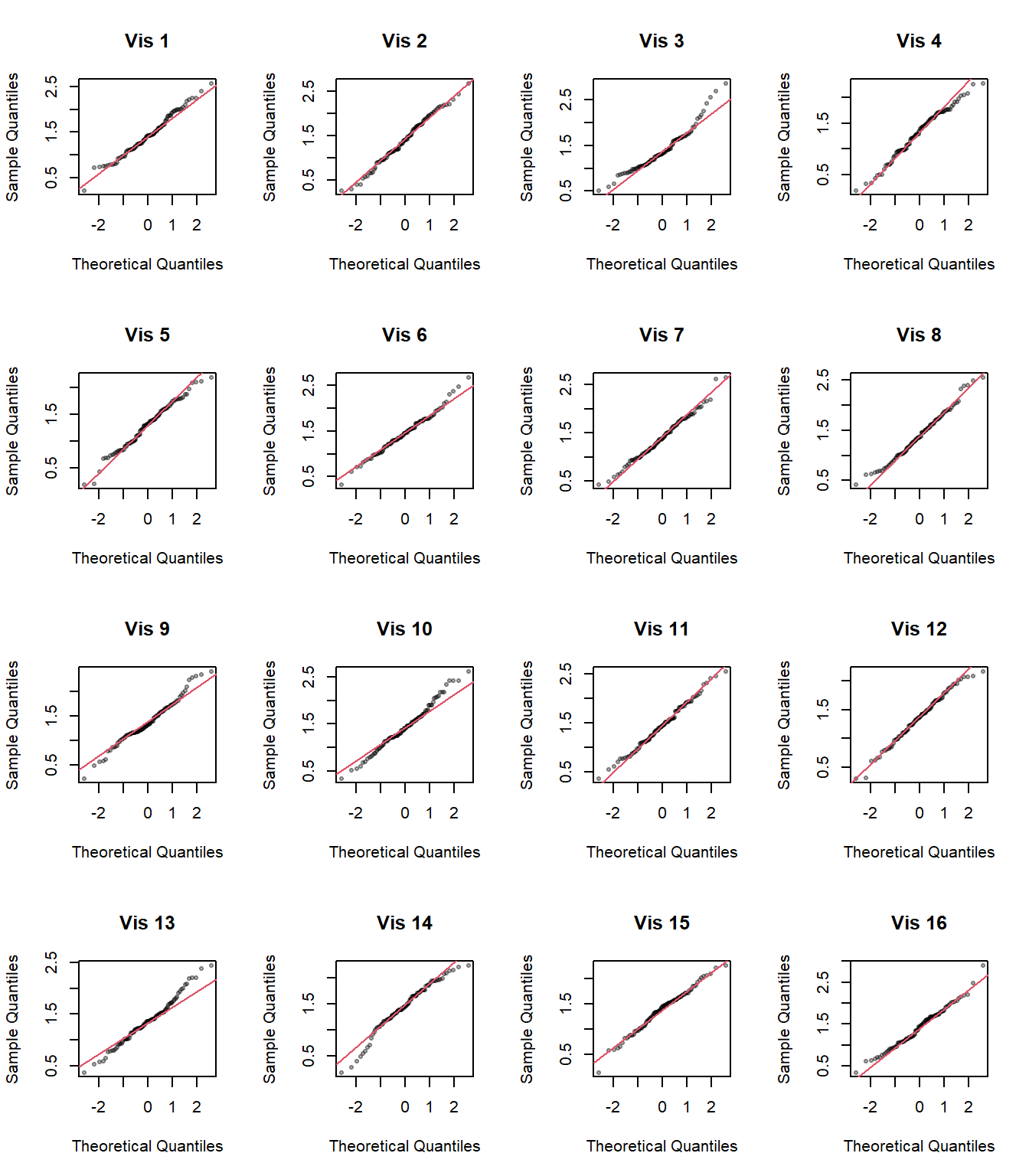
Sea por ejemplo determinar si la distribución de una muestra se ajusta a una distribución normal. La hipótesis nula es que es normal, así que se simulan \(n - 1\) conjuntos de datos normales del mismo tamaño que la muestra y se grafica el qqplot correspondiente.
A manera de ejemplo se toma una base de datos acerca de la comercialización de aguacates. Se desea verificar la hipótesis nula de que el precio promedio se ajusta a una distribución normal.
Obsérvese que los datos simulados tienen la misma media y desviación estándar que los datos reales, además de ser del mismo tamaño.
A continuación se asignará al azar la posición de los datos reales entre los quince conjuntos de datos que sí cumplen la hipótesis nula.
Finalmente se grafican las 16 visualizaciones en una matriz de \(4 \times 4\).