12.2 Integración de Pandas con Matplotlib.
El objeto Dataframe tiene métodos asociados con el módulo Matplotlib, permitiendo aplicar todo lo presentado sobre éste.
from pandas import DataFrame
import matplotlib.pyplot as plt
limite_inferior = [0, 1, 2, 3]
valor = [1, 2, 3, 4]
limite_superior = [2, 3, 4, 5]
d = {'Limite inferior': limite_inferior,
'Valor': valor,
'Limite superior': limite_superior}
df = DataFrame(data = d)
ax = df.plot(color=["Blue", "Red", "Blue"])
lines, labels = ax.get_legend_handles_labels()
_ = ax.legend([lines[0], lines[1]], ["Límites", "Valor"])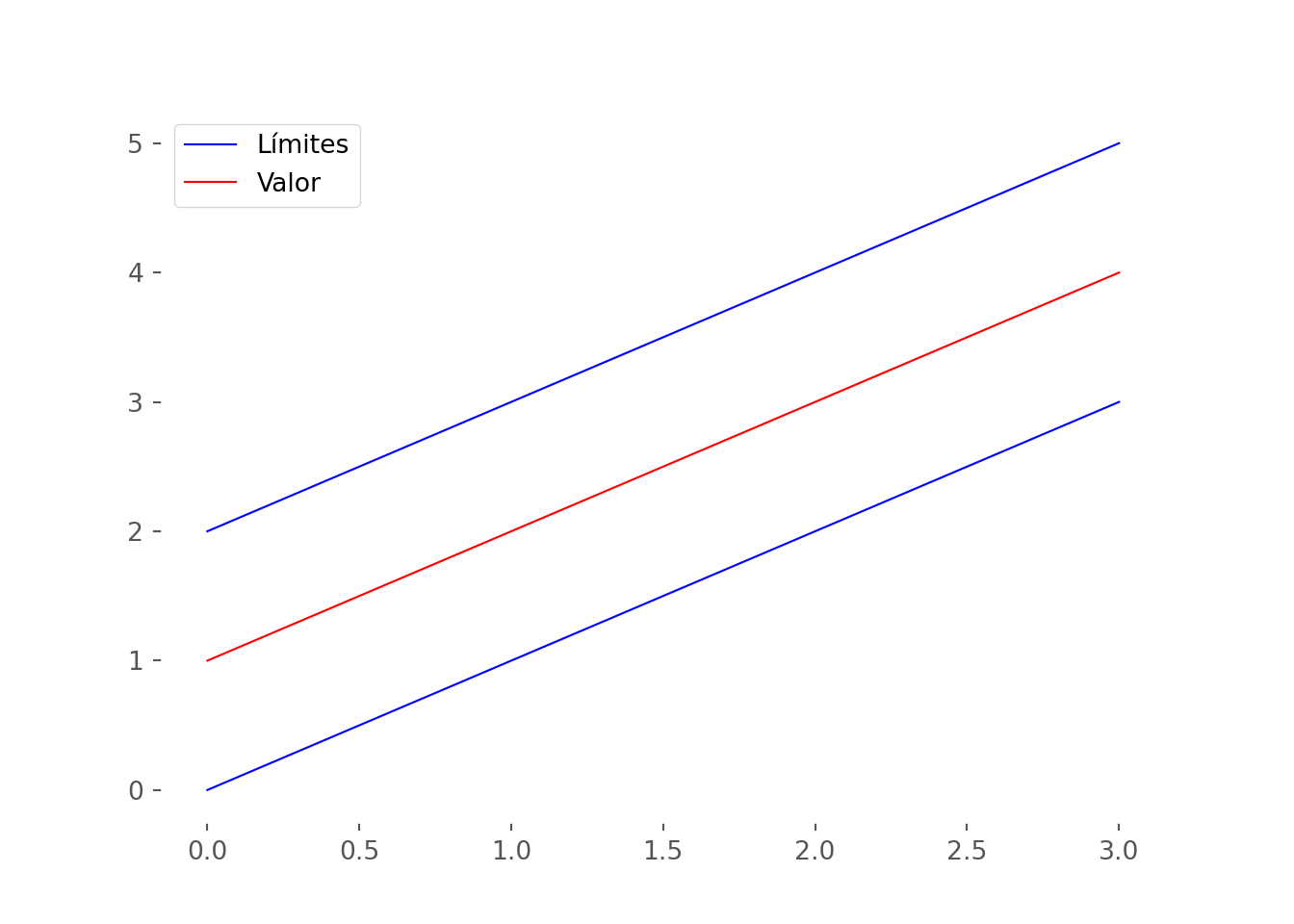
Para ver los métodos “plot” del objeto data frame, ver https://pandas.pydata.org/pandas-docs/version/0.25.0/reference/frame.html#plotting
Ejemplo
import pandas as pd
df = pd.read_csv("../Datos/saber11_2019.csv", sep=";")
# print(df.shape)
# df.head()
df['ESTU_GENERO'].value_counts().sort_values().plot(kind = 'bar', color = ['cornflowerblue', 'indianred'])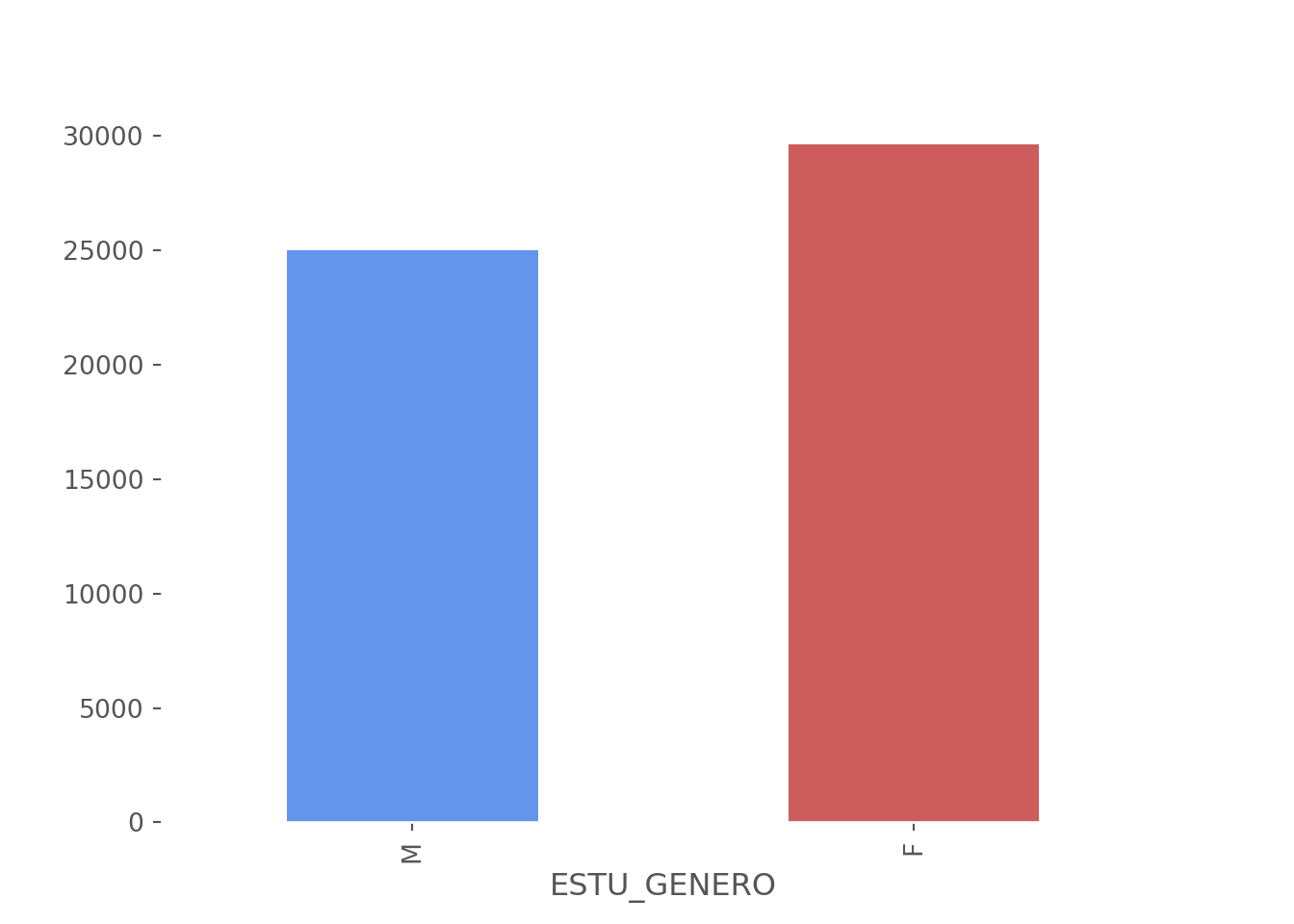
Ejercicio
Despliegue un gráfico de barras que exponga el número de individuos que presentaron la Prueba Saber 11 por departamento. Sólo resalte los cinco departamentos con más estudiantes.
La importancia de manipular los conjuntos de datos para la visualización es la necesidad de estructurarlos de la manera adecuada a la necesidad de cada algoritmo en particular.
import matplotlib.pyplot as plt
_ = plt.figure(figsize=(6,3))
ax = df['ESTU_GENERO'].value_counts().sort_values().plot(kind = 'bar', color = ['darkkhaki', 'darkgoldenrod'])
_ = ax.set_title("Prueba SABER 11")
_ = ax.set_xlabel('Sexo')
_ = ax.set_ylabel('Número de estudiantes')
_ = plt.xticks(rotation=0)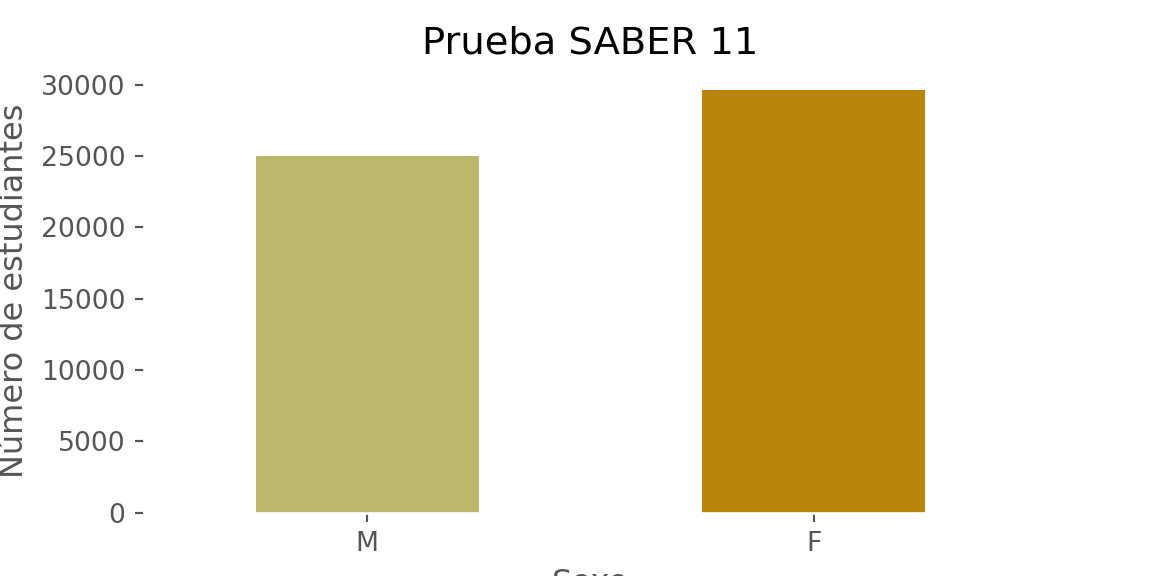
En el siguiente código se calcula la cantidad de hombres y mujeres por naturaleza del colegio con la intención de mostrar barras agrupadas. Una opción es indicar que hay subplots, sin especificar el número de ejes. Al definir dos ejes, queda claro. En cada eje se añade el atributo del tipo de canal que se pretende utilizar.
import numpy as np
import matplotlib.pyplot as plt
etiquetas = ["Oficial", "No Oficial"]
hombres = df[df["ESTU_GENERO"] == "M"]["COLE_NATURALEZA"].value_counts()
mujeres = df[df["ESTU_GENERO"] == "F"]["COLE_NATURALEZA"].value_counts()
ancho = 0.2
indice = np.arange(2)
fig, eje = plt.subplots()
barra1 = eje.bar(indice, hombres, ancho, color = "cornflowerblue")
barra2 = eje.bar(indice + ancho, mujeres, ancho, color = "mediumseagreen", tick_label = etiquetas)
plt.ylabel("Cantidad")## Text(0, 0.5, 'Cantidad')## <matplotlib.legend.Legend object at 0x0000012D8A5EBE20>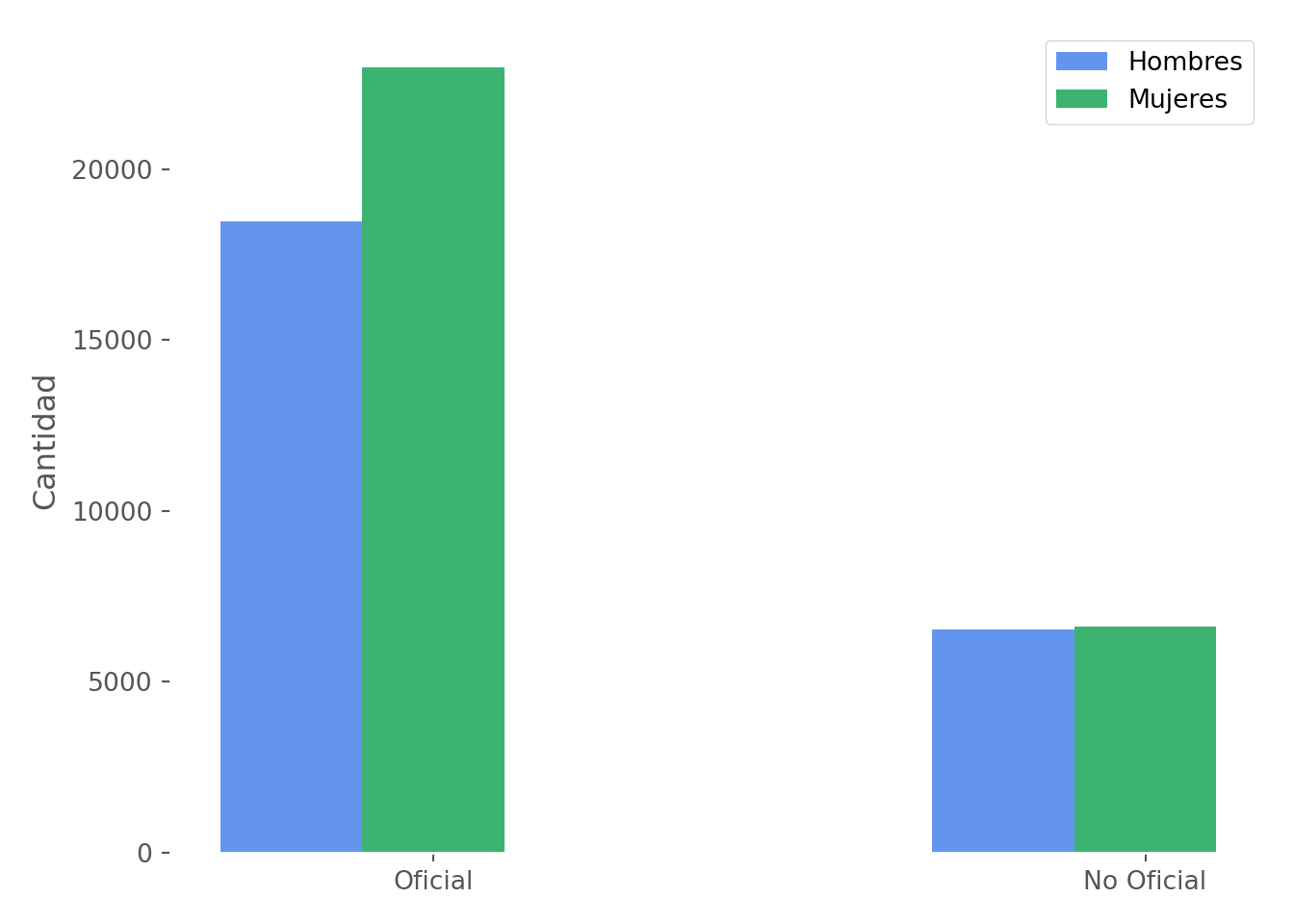
Para realizar el mismo gráfico con barras apiladas basta con alterar el argumento de la barra2, añadiendo ‘bottom = hombres’ y ajustando el indice correspondiente. No obstante, es más interesante comparar por sexo, así que se invierte el orden de ambas variables categóricas:
etiquetas = ["Mujeres", "Hombres"]
oficiales = df[df["COLE_NATURALEZA"] == "OFICIAL"]["ESTU_GENERO"].value_counts()
noOficiales = df[df["COLE_NATURALEZA"] == "NO OFICIAL"]["ESTU_GENERO"].value_counts()
ancho = 0.2
indice = np.arange(2)
fig, eje = plt.subplots()
barra1 = eje.bar(indice, oficiales, ancho, color = "#FF7C33")
barra2 = eje.bar(indice, noOficiales, ancho, bottom = oficiales, color = "#0C9999", tick_label = etiquetas)
plt.ylabel("Cantidad")## Text(0, 0.5, 'Cantidad')## <matplotlib.legend.Legend object at 0x0000012D8A647FD0>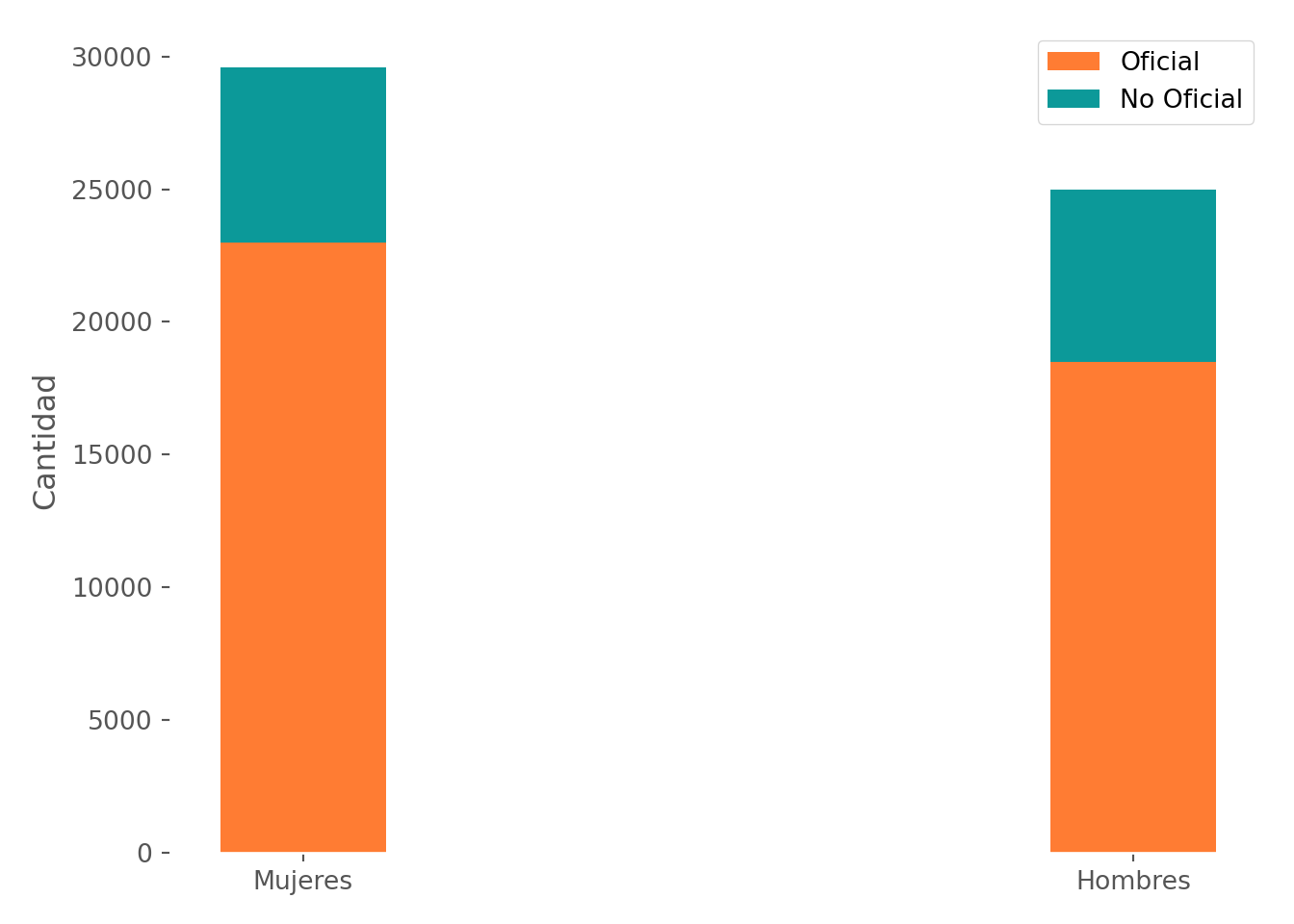
Obsérvese que se cambian los colores para dejar claro que se ha intercambiado la agrupación de las barras.
Mosaico
Es una alternativa para presentar simultáneamente dos variables categóricas.
from statsmodels.graphics.mosaicplot import mosaic
plt.rcParams['font.size'] = 10.0
mosaic(df, ['COLE_NATURALEZA', 'ESTU_GENERO'])## (<Figure size 700x500 with 3 Axes>, {('OFICIAL', 'M'): (0.0, 0.0, 0.755575319877256, 0.44408956591422694), ('OFICIAL', 'F'): (0.0, 0.4474118250504396, 0.755575319877256, 0.5525881749495605), ('NO OFICIAL', 'M'): (0.7605504442553654, 0.0, 0.2394495557446346, 0.49458454822104536), ('NO OFICIAL', 'F'): (0.7605504442553654, 0.497906807357258, 0.2394495557446346, 0.5020931926427419)})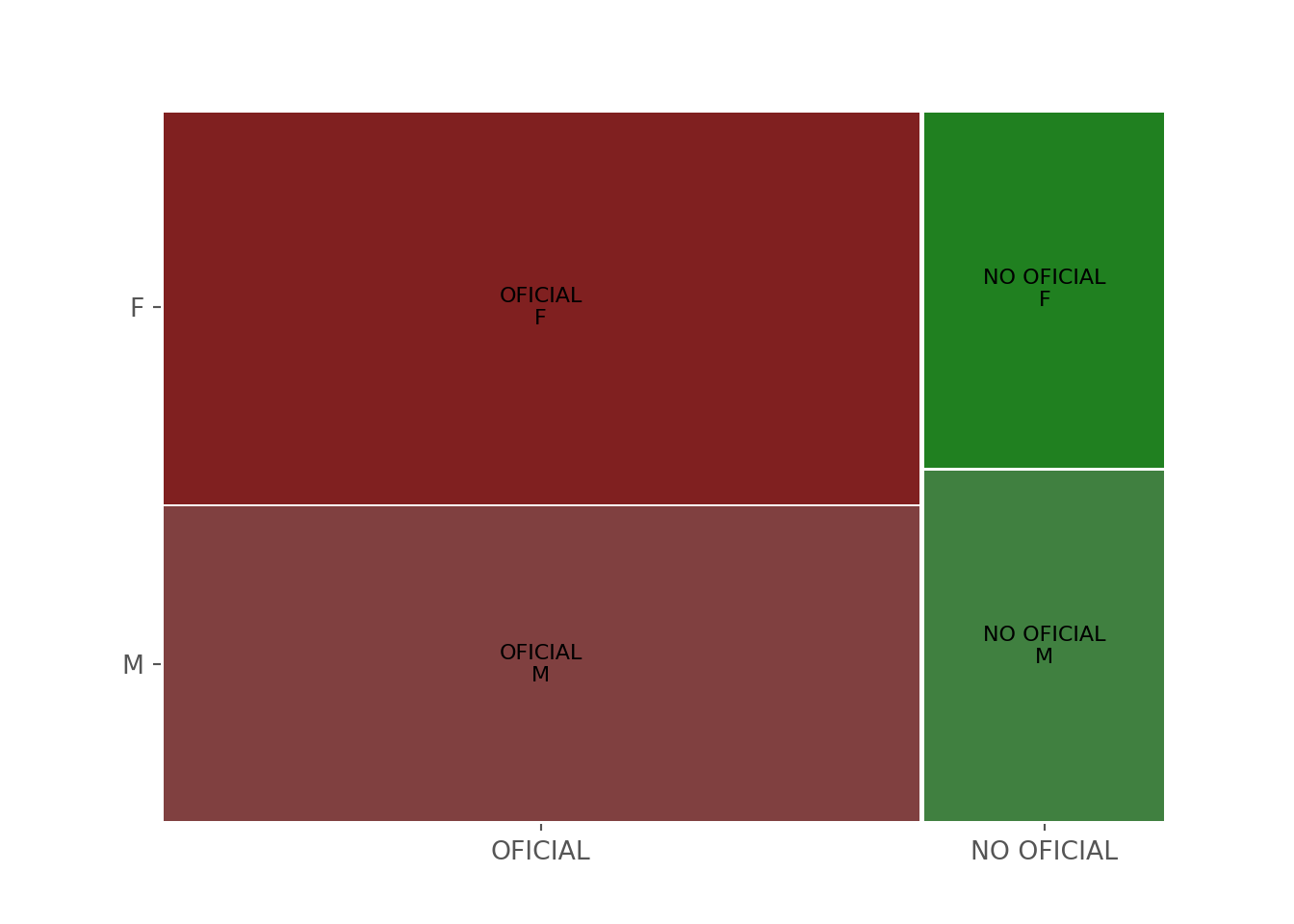
Otras Gráficas
Hay otros estilos de gráficas disponibles por medio del argumento kind en el método plot(). La lista completa:
Sobre variables categóricas:
barpara barras verticales.barhpara barras horizontales.piepara diagramas de sectores.
Sobre variables cuantitativas continuas:
histpara histogramasboxpara diagramas de caja.kdeodensitypara diagramas de densidad.
Para series de tiempo sobre variables cuantitativas continuas:
linepara diagramas de línea.areapara diagramas de área.
Sobre pares de variables cuantitativas continuas:
scatterpara diagramas de dispersión.hexbinpara diagramas de dispersión hexágonales.