Capítulo 29 Árboles.
Recuérdese que los árboles son una sub-clasificación de las redes, en donde no hay ciclos, son direccionales y jerárquicas.
Se requiere el uso del módulo scipy.
Sea leída una base de datos de la administración de una gran superficie o “Mall”.
import matplotlib.pyplot as plt
import pandas as pd
import scipy
import numpy as np
df = pd.read_csv(data_dir/"Mall_Customers.csv")
df.head()## ClienteID Sexo ... Ingresos mensuales(miles) Indice de gasto (1-100)
## 0 1 Masculino ... 15 39
## 1 2 Masculino ... 15 81
## 2 3 Femenino ... 16 6
## 3 4 Femenino ... 16 77
## 4 5 Femenino ... 17 40
##
## [5 rows x 5 columns]## Index(['ClienteID', 'Sexo', 'Edad', 'Ingresos mensuales(miles)',
## 'Indice de gasto (1-100)'],
## dtype='object')La base de datos presenta para un conjunto de clientes su sexo, edad, nivel de ingresos y un índice de gastos. Desconocemos cómo se generó dicho índice. Debemos suponer que hace referencia a qué monto gasta en el Mall.
Suponga se desea categorizar a los clientes del Mall mediante un algoritmo de conglomerados.
La función linkage del módulo scipy.cluster.hierarchy realiza lo que se denomina un agrupamiento (clustering) jerárquico.
La entrada y puede ser una matriz de distancias ya calculadas, o una matriz (2-D) de vectores de observación, de tal manera que internamente calcule las distancias.
Al correr el algoritmo, éste devuelve una matriz Z de 4 en 4. Los datos del vector de observación son las dos primera scolumnas Z[i, 0] y Z[i, 1]. La distancia viene dada por Z[i, 2]. El cuarto valor, Z[i, 3], representa el número de observaciones en el clúster recién formado.
Para la visualización del resultado nos interesan las columnas tercera y cuarta
## (200, 2)Obsérvese el resultado de realizar el agrupamiento:
import scipy.cluster.hierarchy as sch
grupos = sch.linkage(X, method = 'ward')
# convert the array to a DataFrame and add column headers
df = pd.DataFrame(grupos, columns=['Grupo_1', 'Grupo_2', 'Distancia', 'N.puntos'])
# show the first 10 rows of the DataFrame
print(df.head(10))## Grupo_1 Grupo_2 Distancia N.puntos
## 0 65.0 68.0 0.0 2.0
## 1 48.0 49.0 0.0 2.0
## 2 156.0 158.0 0.0 2.0
## 3 129.0 131.0 0.0 2.0
## 4 21.0 23.0 1.0 2.0
## 5 51.0 53.0 1.0 2.0
## 6 60.0 61.0 1.0 2.0
## 7 67.0 69.0 1.0 2.0
## 8 64.0 66.0 1.0 2.0
## 9 79.0 82.0 1.0 2.0## Grupo_1 Grupo_2 Distancia N.puntos
## 189 352.0 382.0 64.537406 49.0
## 190 371.0 385.0 69.523155 30.0
## 191 377.0 381.0 81.179359 23.0
## 192 383.0 389.0 106.650579 85.0
## 193 388.0 390.0 112.818203 39.0
## 194 384.0 386.0 113.886017 32.0
## 195 391.0 392.0 245.654601 108.0
## 196 387.0 395.0 262.562634 129.0
## 197 393.0 394.0 394.859658 71.0
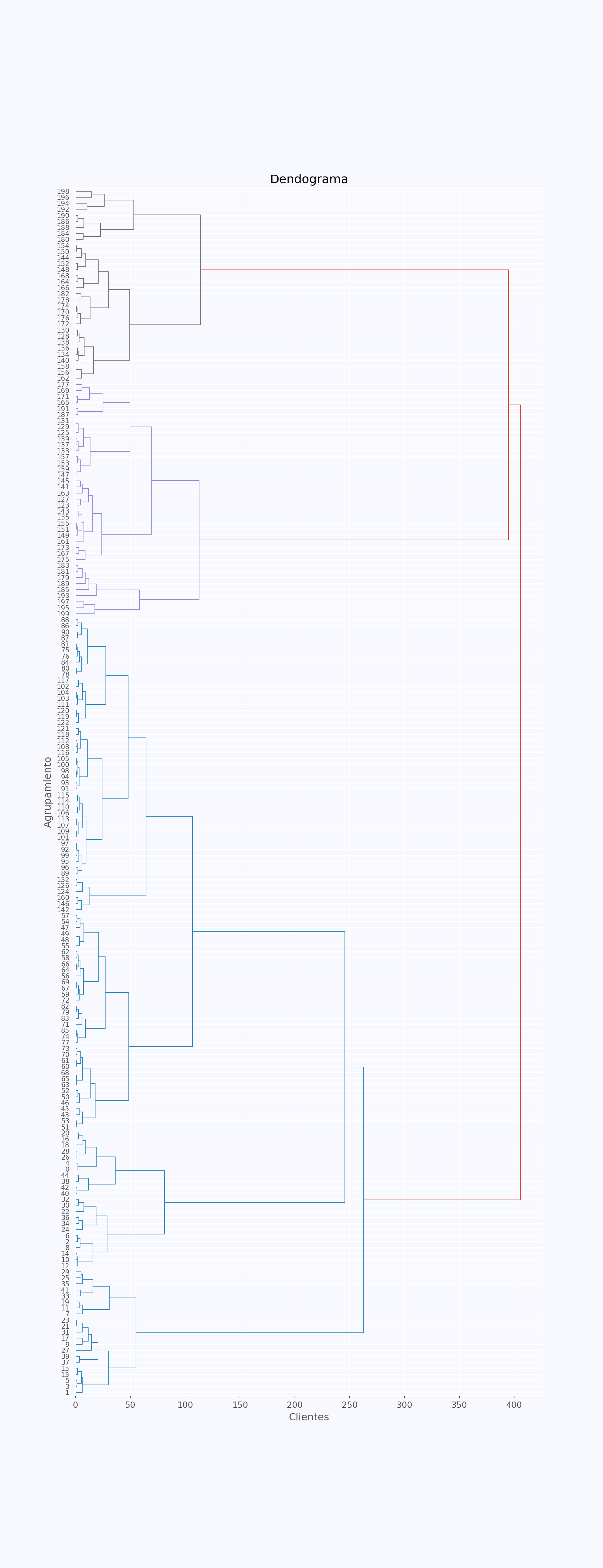
## 198 396.0 397.0 405.660041 200.0Para la visualización se aplica el método dendogram:
## Text(0.5, 1.0, 'Dendograma')## Text(0.5, 0, 'Clientes')## Text(0, 0.5, 'Agrupamiento')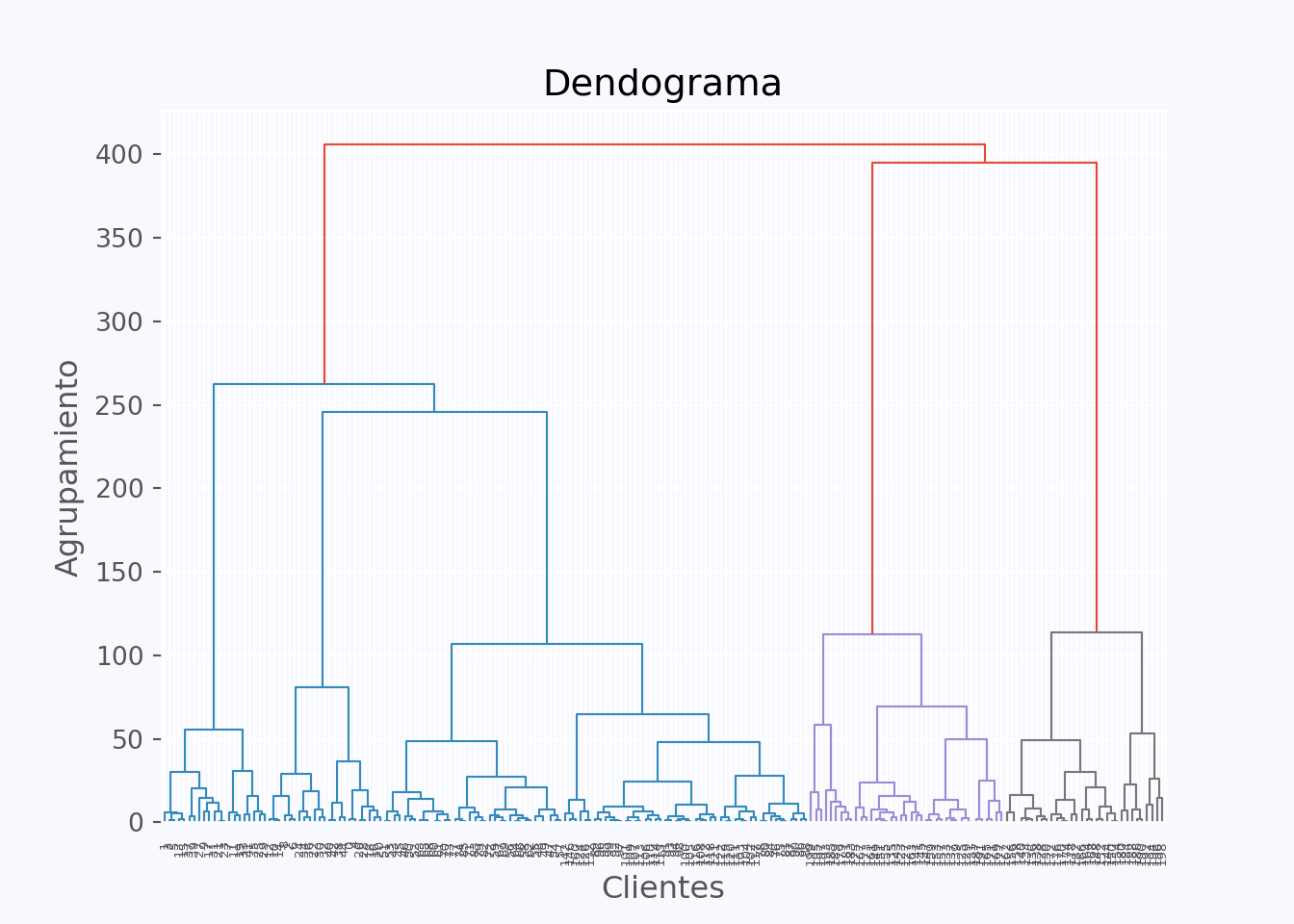
Se puede ensanchar para mejorar la visualización:
fig, ax = plt.subplots(figsize=(20, 10))
dendrogram = sch.dendrogram(grupos, ax=ax, leaf_font_size=10)
plt.title('Dendograma')## Text(0.5, 1.0, 'Dendograma')## Text(0, 0.5, 'Clientes')## Text(0.5, 0, 'Agrupamiento')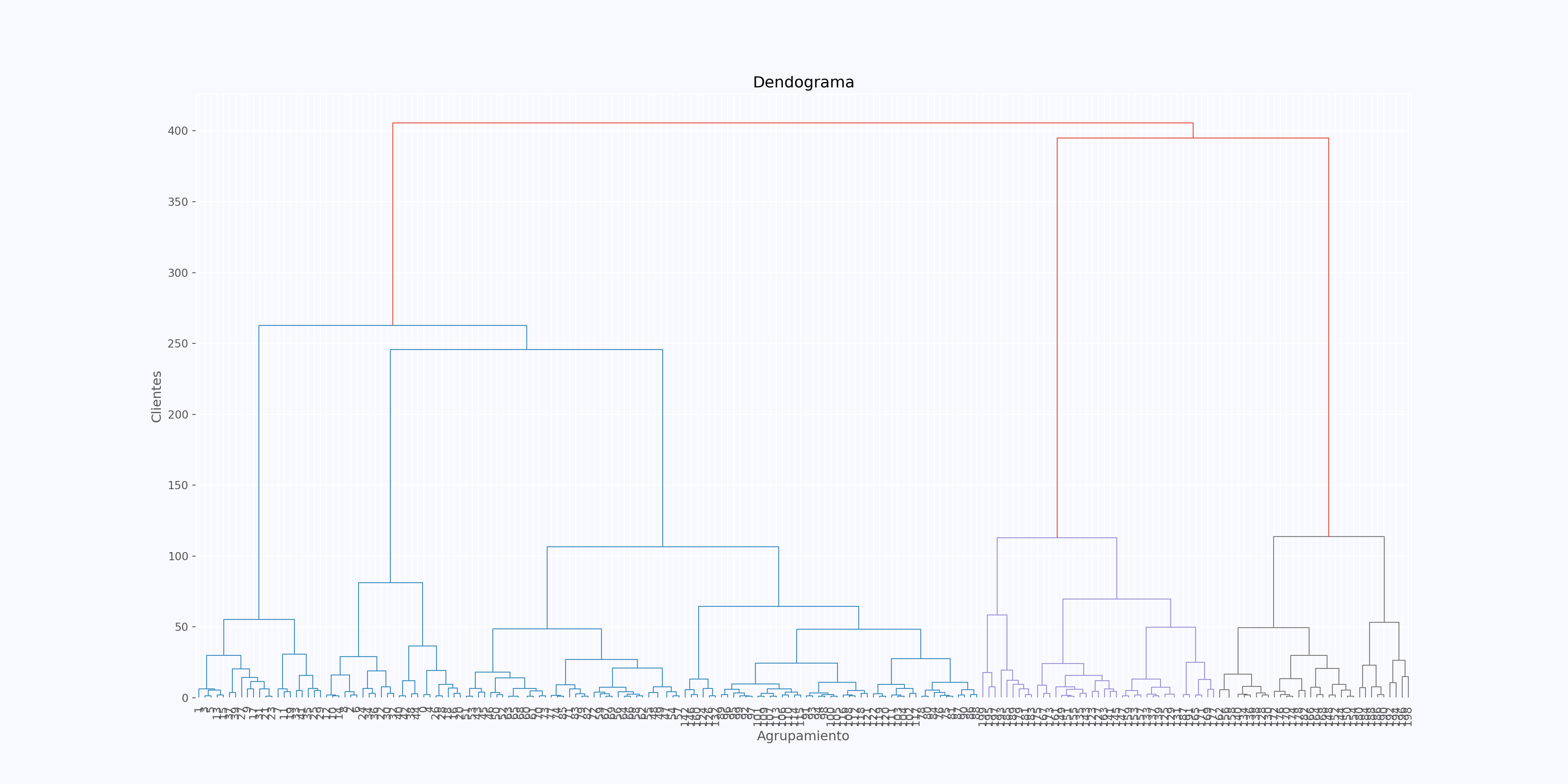
Como en toda visualización con muchas categorías, intercambiar los ejes x y y mejora la visibilidad siempre y cuando sea de interés identificar las hojas de cada grupo, en cuyo caso habrá que jugar con el alto del lienzo y el tamaño de las etiquetas del eje:
fig, ax = plt.subplots(figsize=(10, 26))
dendrogram = sch.dendrogram(grupos, ax=ax, leaf_font_size=8, orientation='right')
plt.title('Dendograma')## Text(0.5, 1.0, 'Dendograma')## Text(0.5, 0, 'Clientes')## Text(0, 0.5, 'Agrupamiento')