27.5 Histogramas y distribuciones de densidad
Los histogramas y las distribuciones de densidad representan variables numéricas continuas.
El histograma tiene su propia geometría:
ggplot(data = saber) +
aes(x= punt_global) +
geom_histogram(fill= "white", color = 'gray65') +
labs(x = "Puntaje global", y = "Frecuencia",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")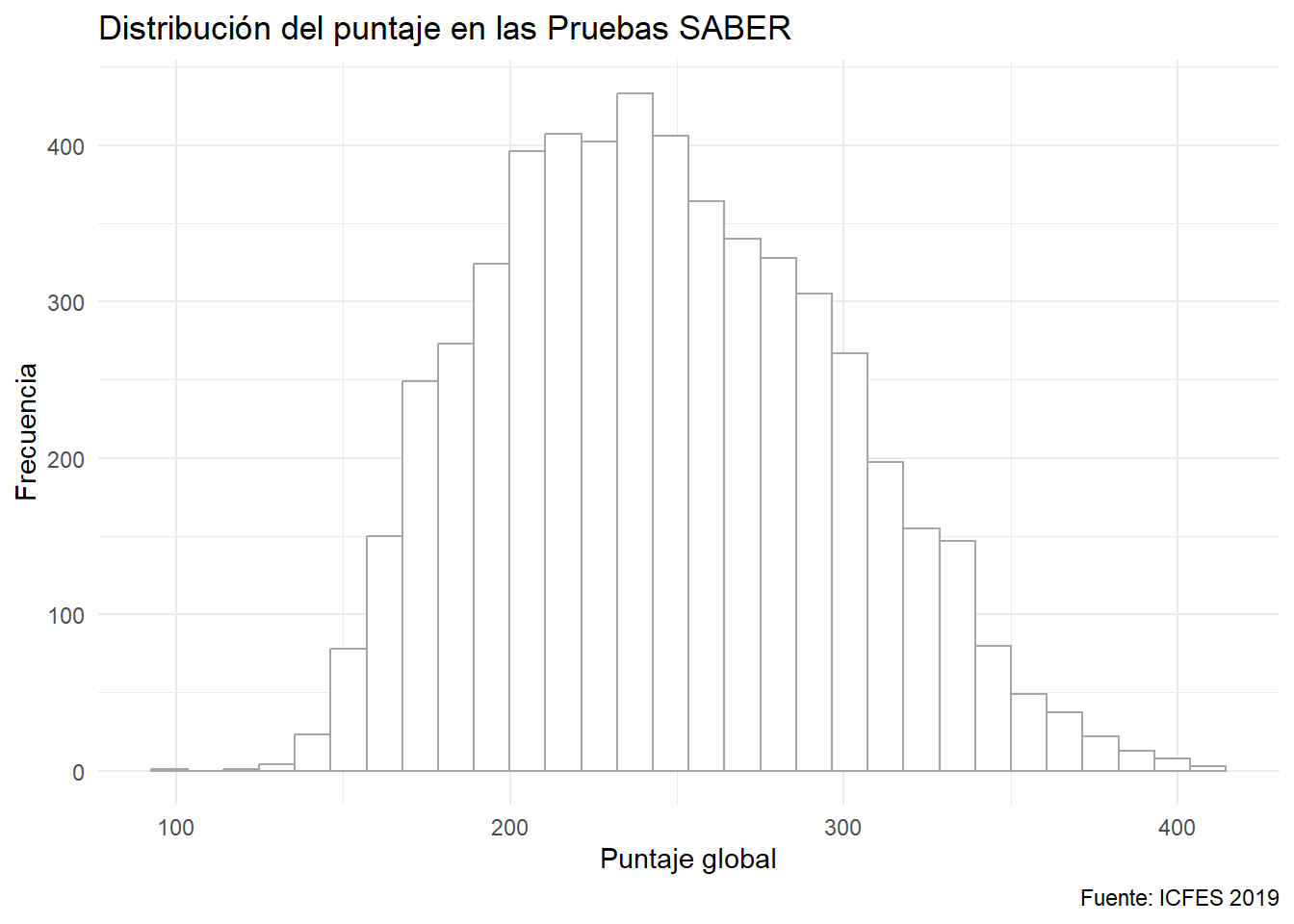
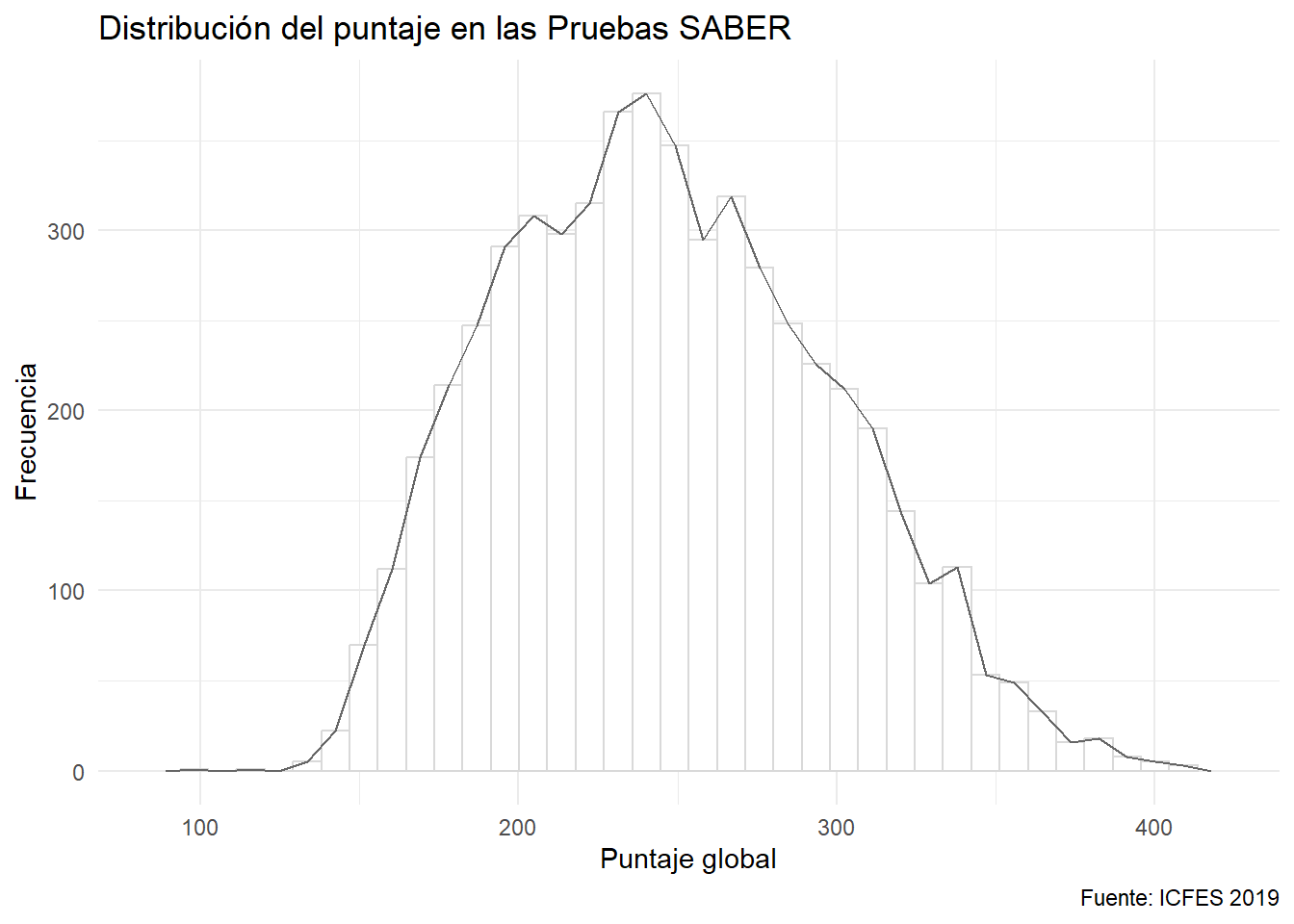
Por defecto, suele darle tono al área de las barras, pero lo importante es a altura, por tanto, no debería colorearse la barra. Es importante que las barras estén juntas. Está representando la agrupación en rangos de una variable continua.
En los diferentes paquetes se calcula el número de barras de manera oculta al usuario, si bien hay tres métodos principales: Sturges, Scott y Freedman-Diaconis. Suele usarse la regla de Sturges por defecto, pero sólo es adecuada si la distribución es unimodal semi-simétrica. En caso de sesgo, son mejores las otras dos reglas.
El número de barras presentadas puede variar la percepción. Muchas suelen generar un perfil con muchas entradas y salidas. Pocas pueden disimular la distribución real:
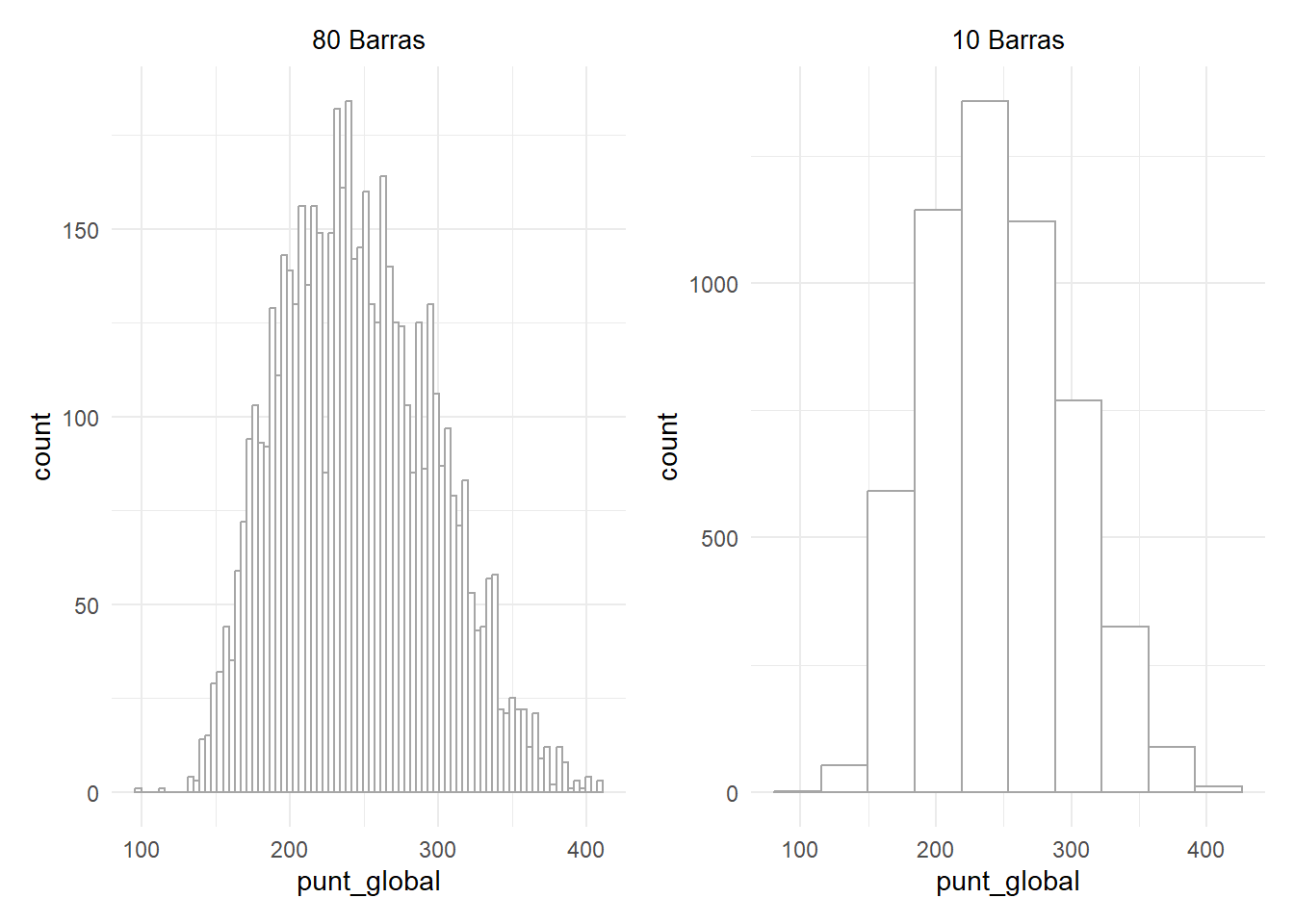
Se puede seleccionar a voluntad el número de barras:
ggplot(data = saber) +
aes(x= punt_global) +
geom_histogram(fill= "white", color = 'gray65', bins = 30) +
labs(x = "Puntaje global", y = "Frecuencia",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")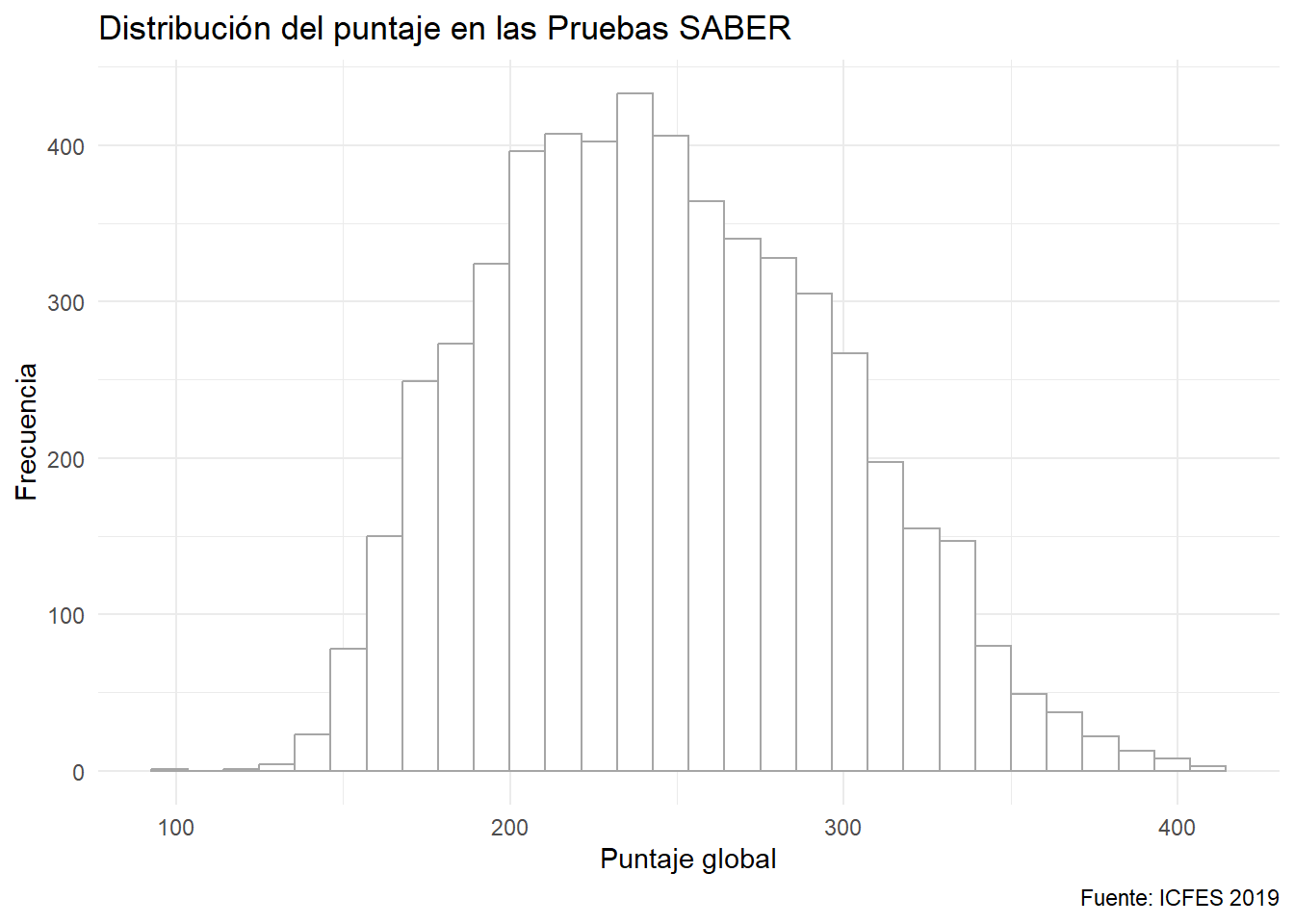
O seleccionar el ancho de éstas y dejar que la función calcule automáticamente cuántas puede presentar de dicho ancho:
ggplot(data = saber) +
aes(x= punt_global) +
geom_histogram(fill= "white", color = 'gray65', binwidth = 15) +
labs(x = "Puntaje global", y = "Frecuencia",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")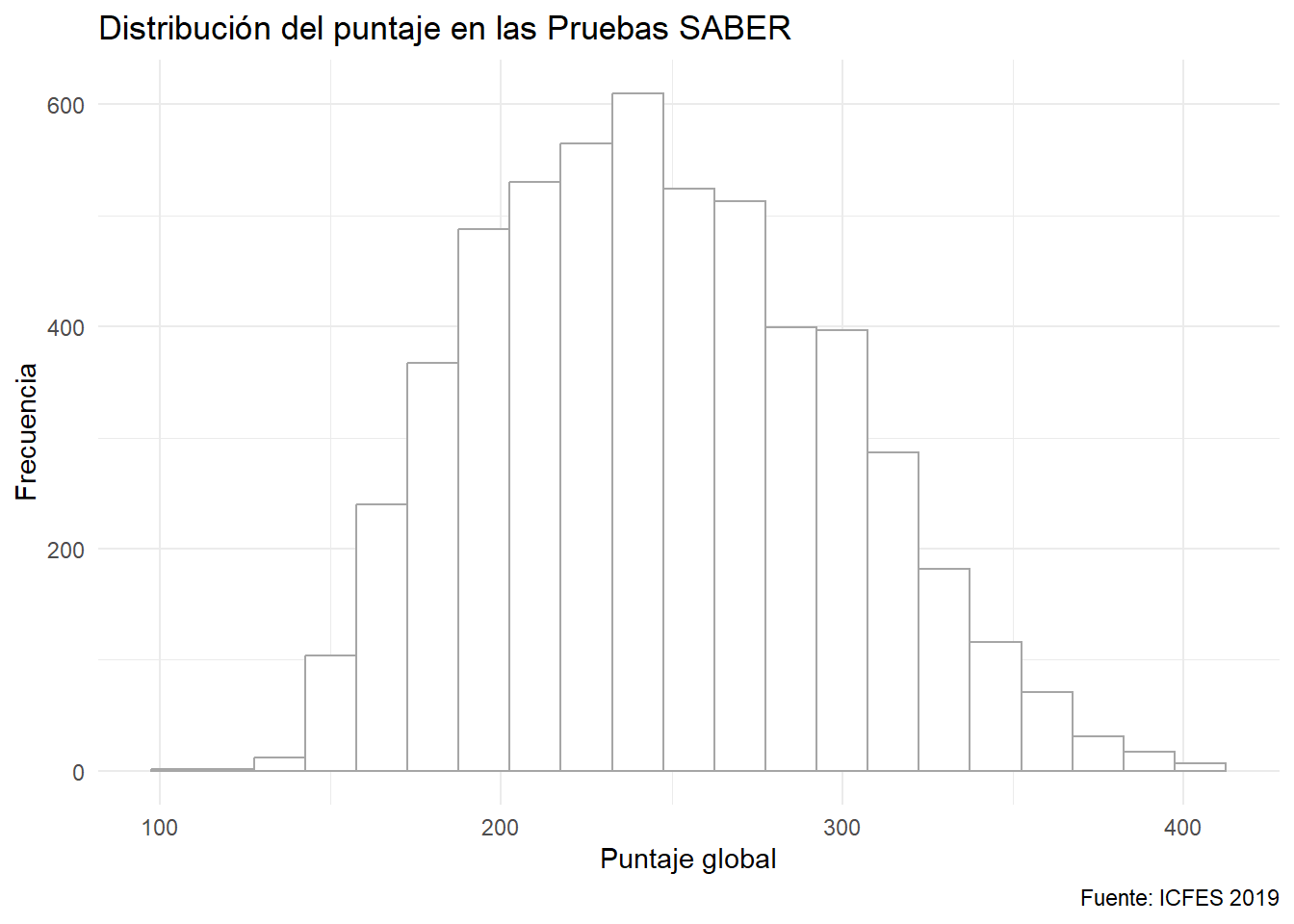
Otra opción, que no presenta el área sino el perfil son los diagramas de polígonos:
ggplot(data = saber) +
aes(x= punt_global, y = after_stat(density)) +
geom_freqpoly(bins = 36, col = "gray40") +
labs(x = "Puntaje global", y = "Densidad",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")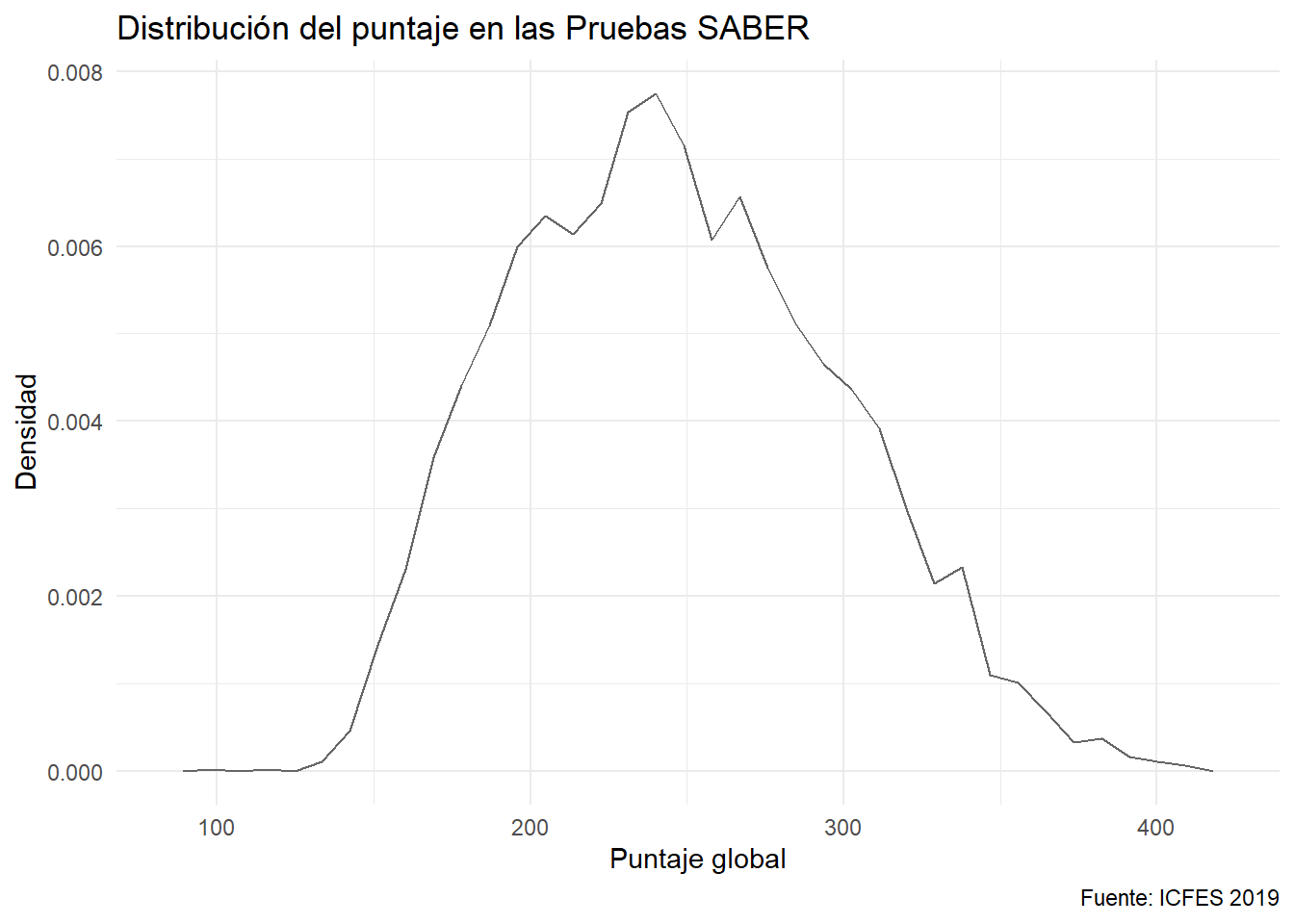
Es lo mismo que un histograma en donde se unieron los puntos medios superiores de cada barra:
Una opción suavizada de los diagramas de polígonos es el diagrama de densidad:
ggplot(data = saber) +
aes(x= punt_global) +
geom_density() +
labs(x = "Puntaje global", y = "Densidad",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")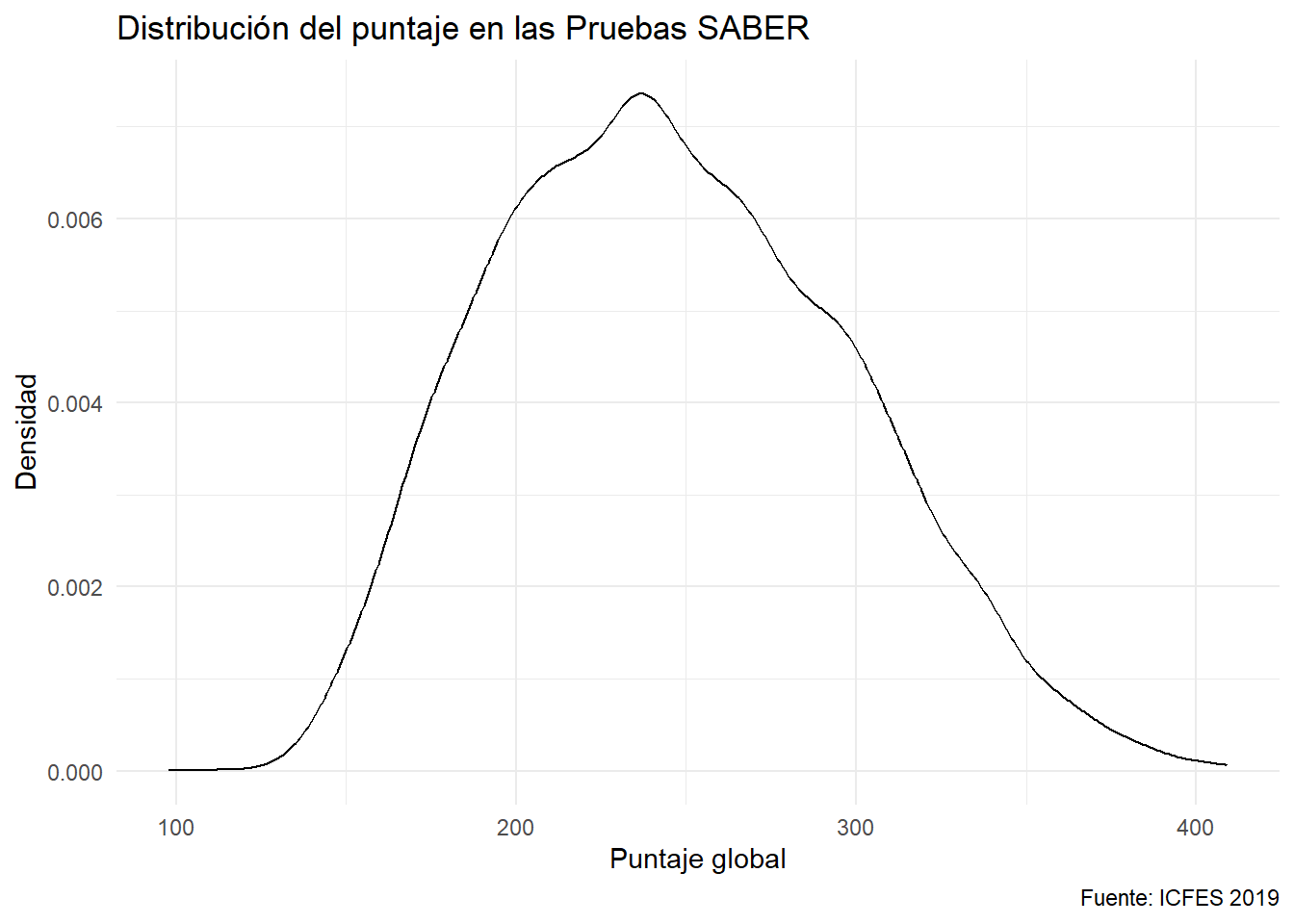
Observe el eje y de los histogramas, diagramas de polígonos y densidad. Los dos primeros presentan conteos. El último se auto-ajustó para presentar un autentico diagrama de densidad. Es decir, el área bajo la curva suma uno.
Como el área tiene significado, está bien darle color:
ggplot(data = saber) +
aes(x= punt_global) +
geom_density(fill = "gray", color = "white", alpha = 0.5) +
labs(x = "Puntaje global", y = "Densidad",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")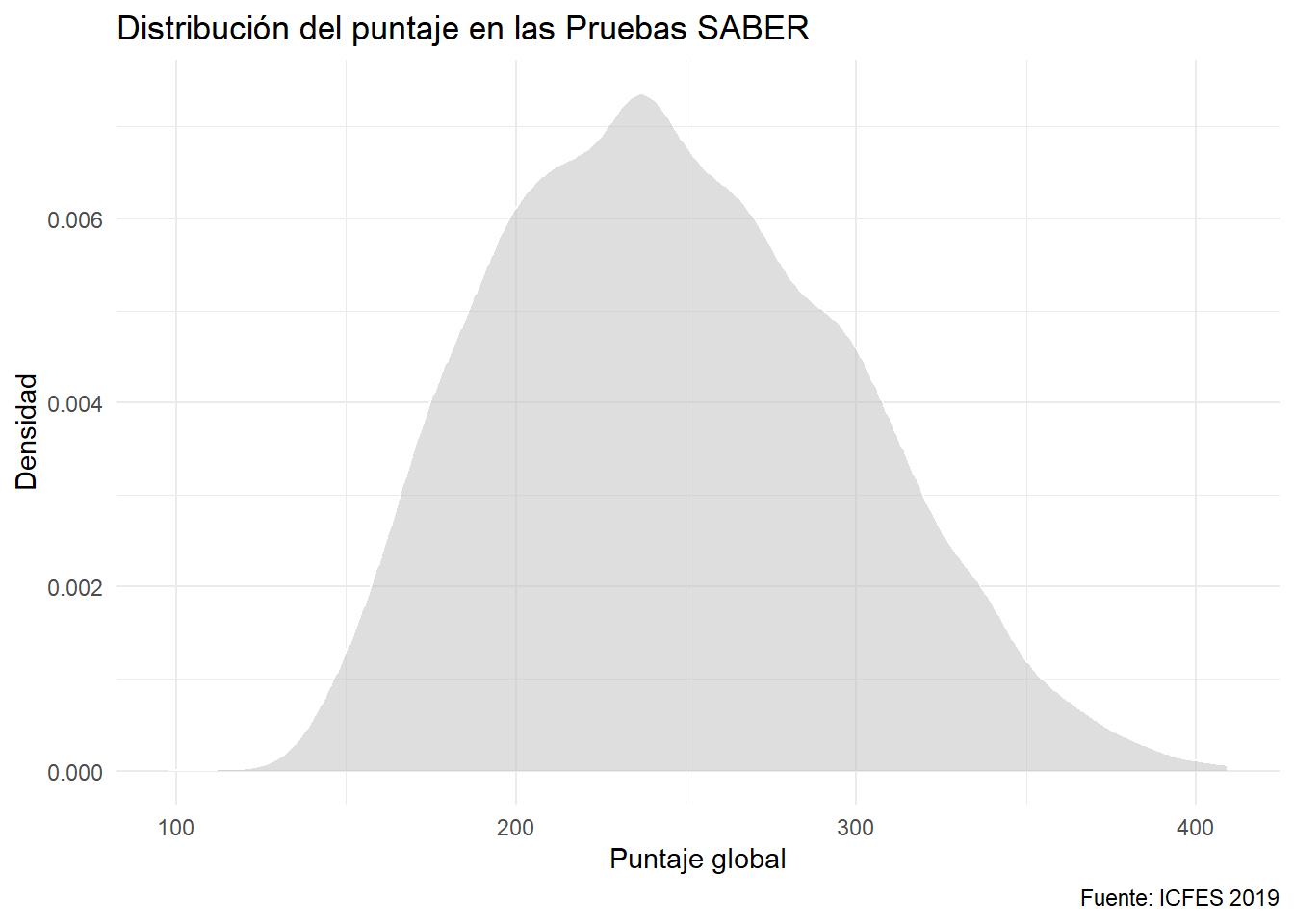
Los histogramas y diagramas de polígonos se pueden convertir en diagramas de densidad especificando y = after_stat(density):
ggplot(data = saber) +
aes(x= punt_global, y = after_stat(density)) +
geom_freqpoly(bins = 36, color = "gray") +
labs(x = "Puntaje global", y = "Densidad",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")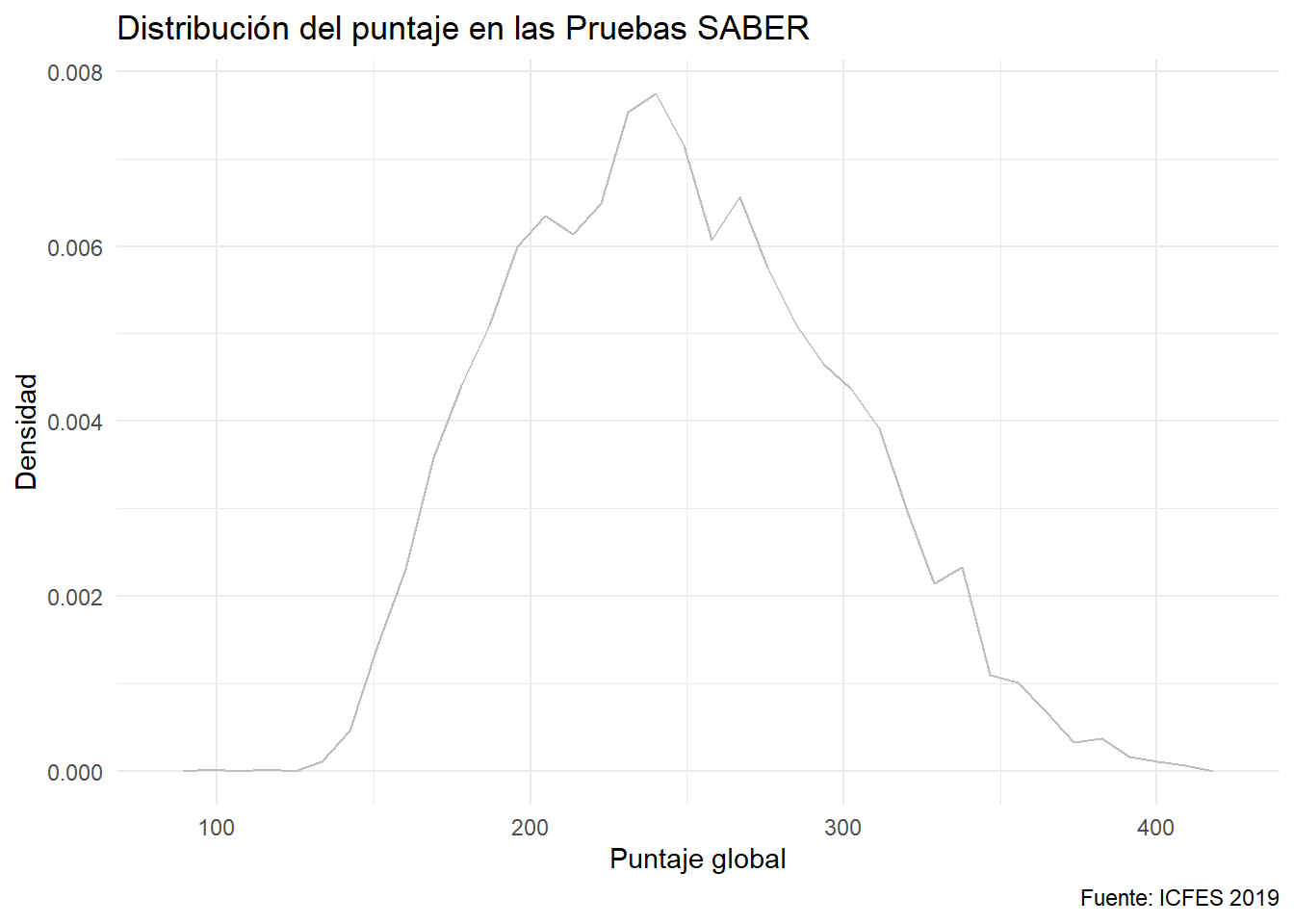
ggplot(data = saber) +
aes(x= punt_global, y = after_stat(density)) +
geom_histogram(bins = 30, color = "white",
fill = 'gray65', alpha = 0.5) +
labs(x = "Puntaje global", y = "Densidad",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")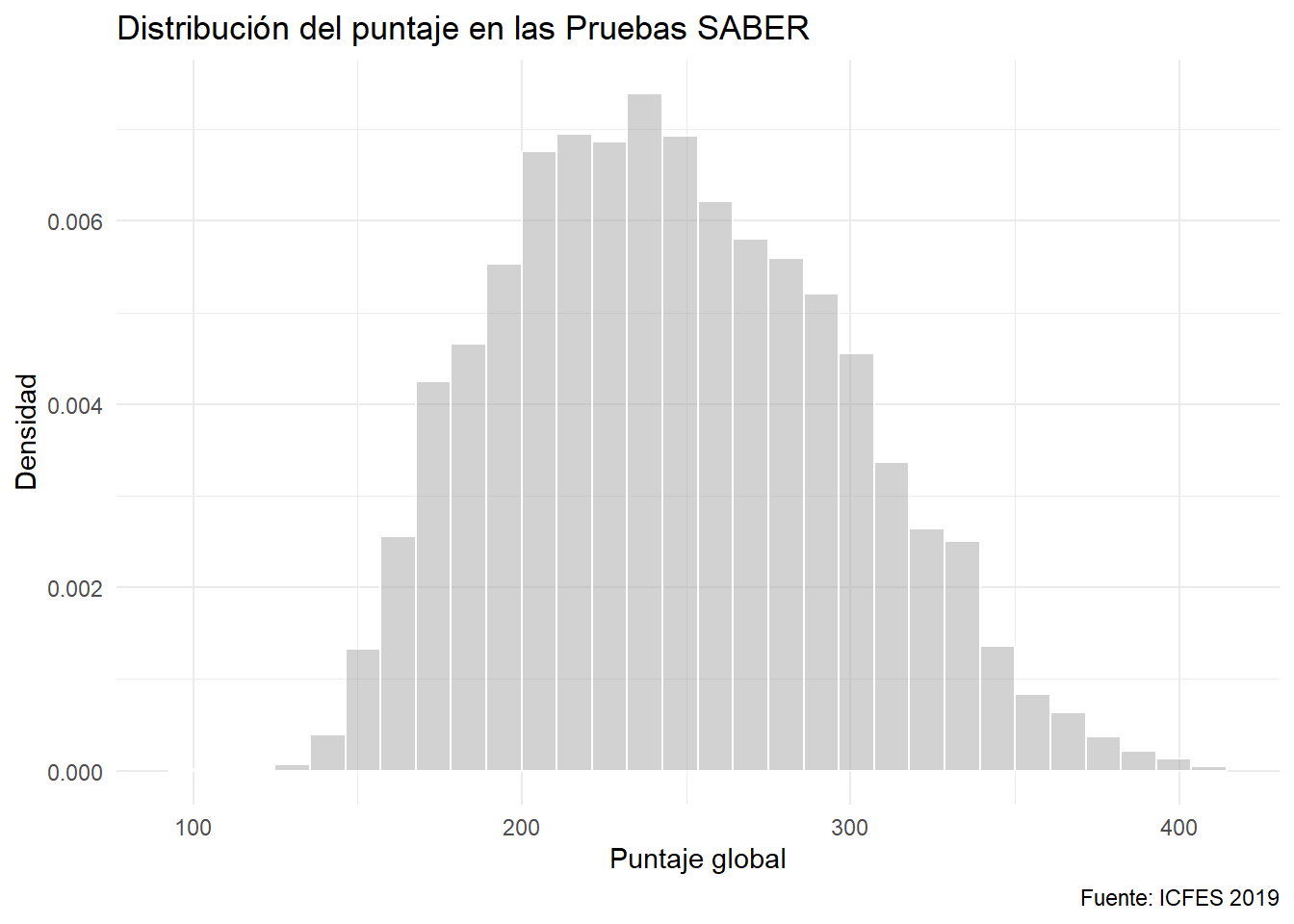
Es posible darle color al área del histograma convertido en densidad. No ocurre lo mismo con el diagrama de polígonos.
Las tres alternativas son aproximaciones a la densidad de los datos.
Los diagramas de densidad utilizan la estrategia de asociar una distribución simétrica a cada punto y luego sumar todas esas distribuciones. (Vea wikipedia)
La distribución simétrica por defecto es la de Gauss. A dichas distribuciones simétricas se las denominan kernels. Pueden elegirse de entre varias opciones:
ggplot(data = saber) +
aes(x= punt_global) +
geom_density(kernel = "epanechnikov", col = "maroon",
linetype = "dashed") +
geom_density(kernel = "rectangular", col = "steelblue") +
labs(x = "Puntaje global", y = "Densidad",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")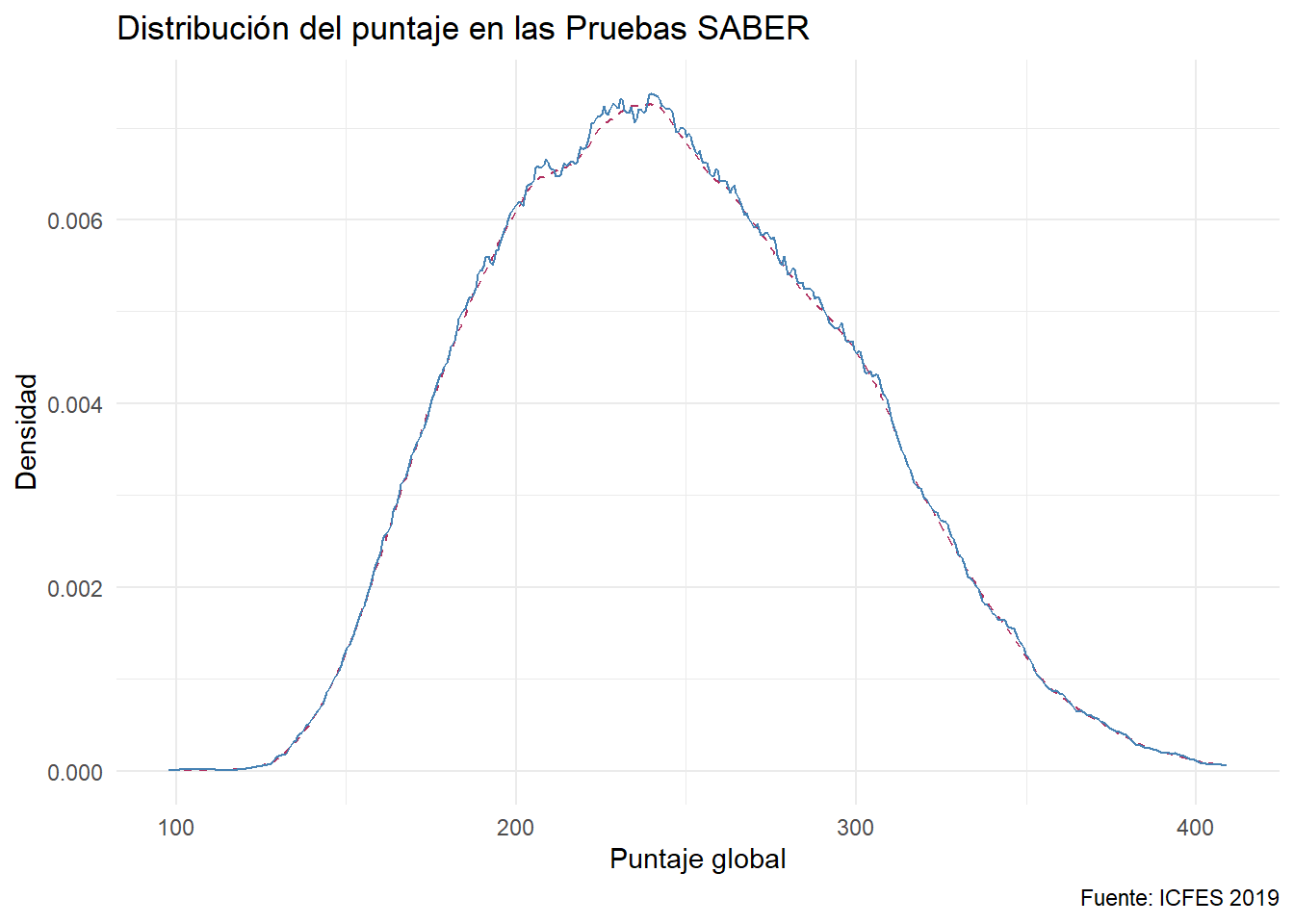
Esta estrategia puede ser engañosa si hay pocos puntos, por tanto se recomienda añadir una capa que presente la ubicación de los puntos de la data. Se realiza en ggplot2 mediante la geometría rug:
ggplot(data = saber) +
aes(x= punt_global) +
geom_density(fill = "gray", color = "white", alpha = 0.5) +
geom_rug(col = "gray") +
labs(x = "Puntaje global", y = "Densidad",
caption = "Fuente: ICFES 2019",
title = "Distribución del puntaje en las Pruebas SABER")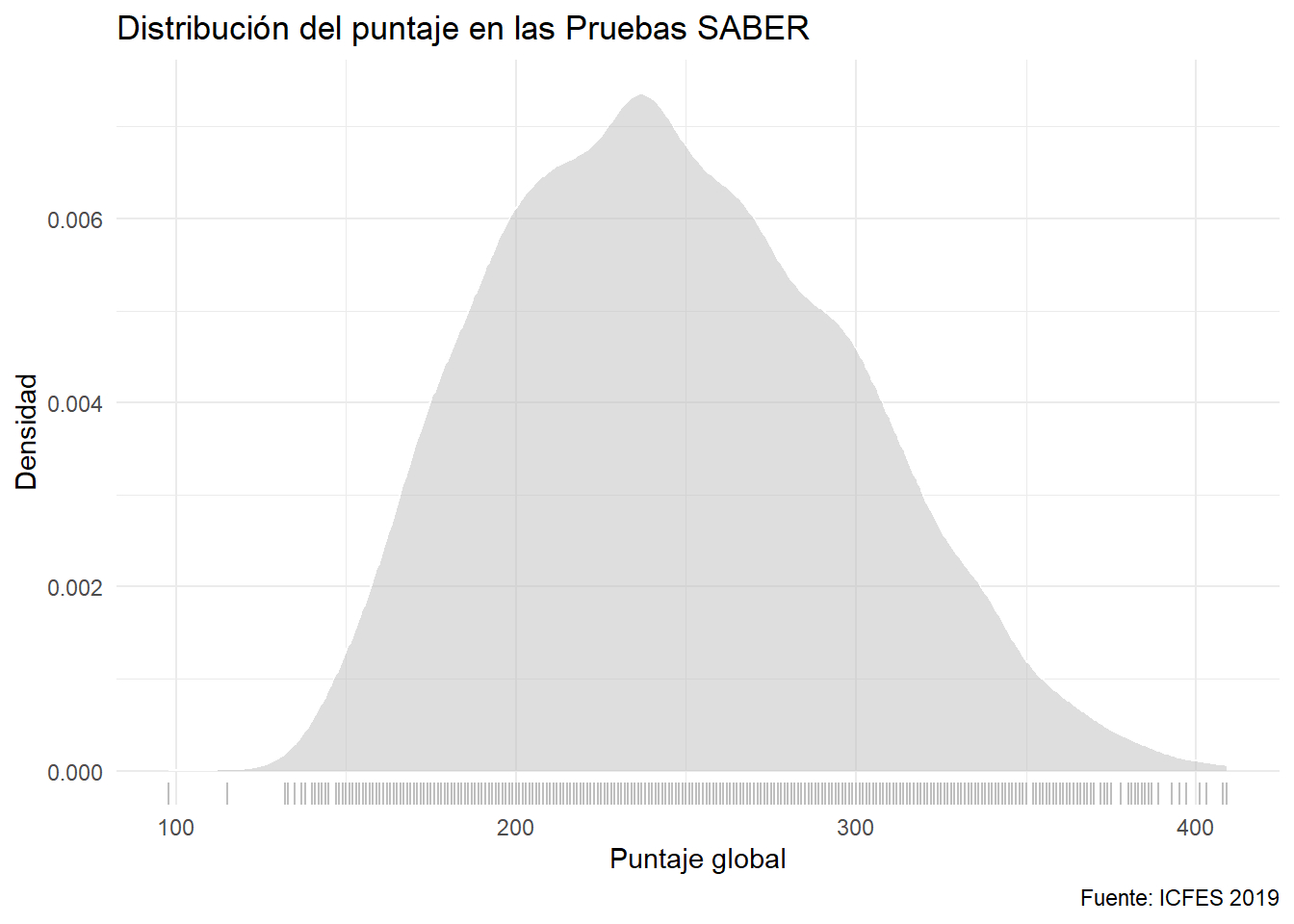
Es interesante comparar la distribución según alguna variable categórica. Se realiza incluyendo en la capa de la estética una:
ggplot(data = saber) +
aes(x= punt_global, color = cole_naturaleza) +
geom_density() +
labs(title = "Comparación entre tipos de Instituciones Educativas",
x = "Puntaje Global",
y = "Densidad",
fill = "Tipo IE",
caption = "Fuente: ICFES 2019")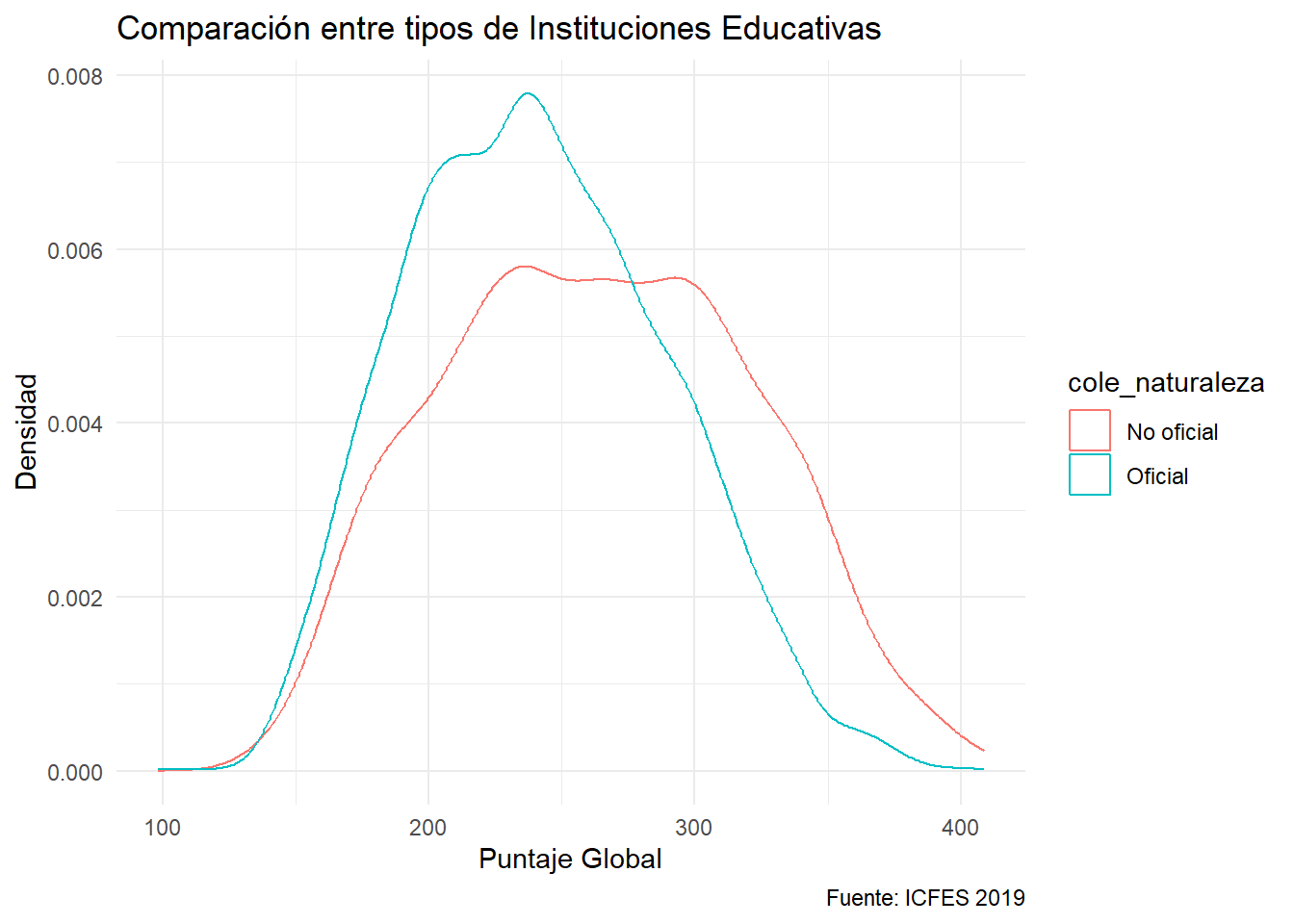
Si se utiliza el área, es conveniente colocar transparencia. Ya se ha utilizado en las visualizaciones anteriores mediante el parámetro alpha. Cero es transparencia total y uno es opacidad total.
ggplot(data = saber) +
aes(x= punt_global, fill = cole_naturaleza) +
geom_density(color = "white", alpha = 0.3) +
labs(title = "Comparación entre tipos de Instituciones Educativas",
x = "Puntaje Global",
y = "Densidad",
fill = "Tipo IE",
caption = "Fuente: ICFES 2019")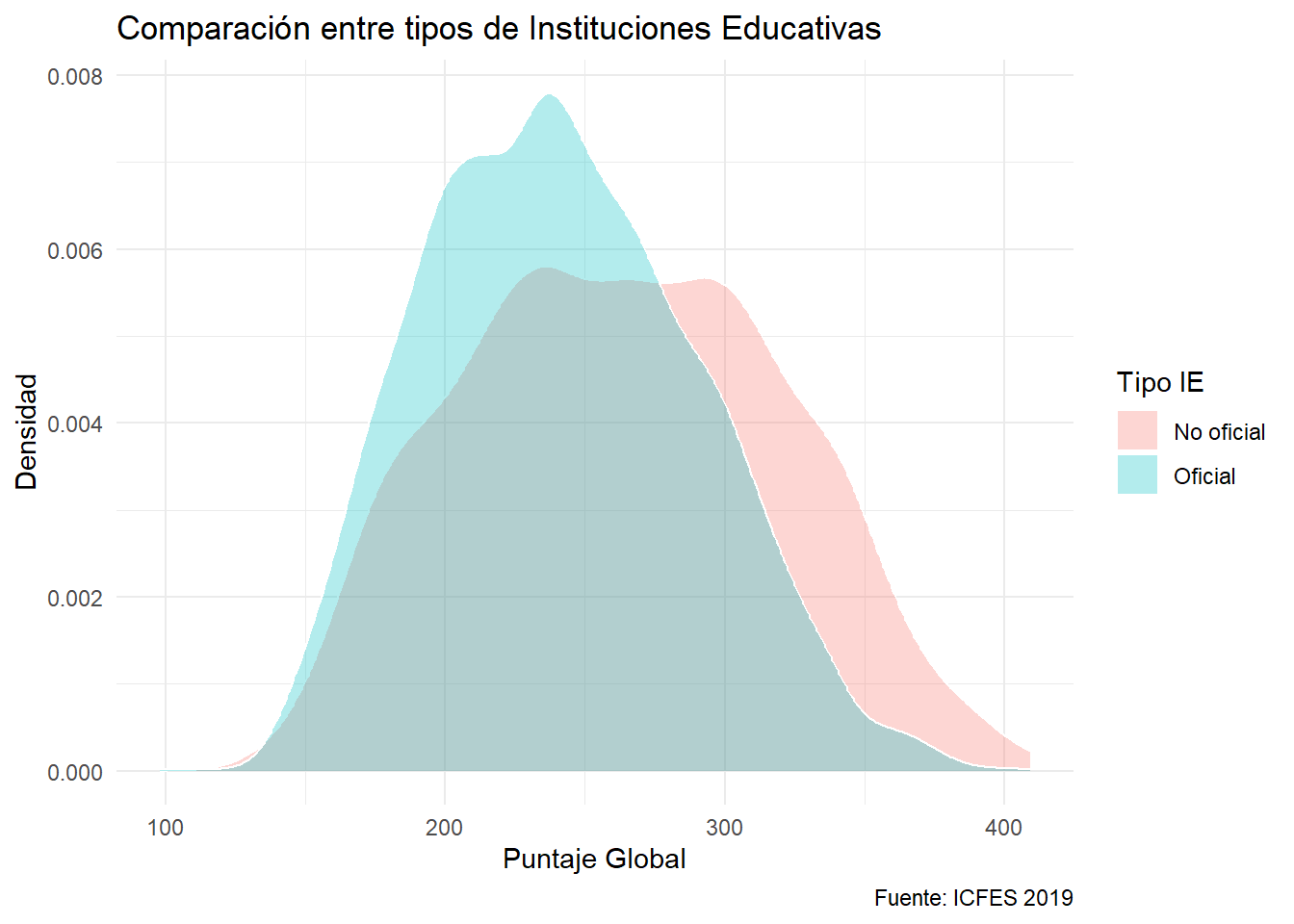
Hasta este punto no se han añadido elementos necesarios a toda visualización. Se añaden mediante la capa de etiquetas: labs
ggplot(data = saber) +
aes(x= punt_global, fill = cole_naturaleza) +
geom_density(color = "white", alpha = 0.3) +
labs(title = "Comparación entre tipos de Instituciones Educativas",
x = "Puntaje Global",
y = "Densidad",
fill = "Tipo IE",
caption = "Fuente: ICFES 2019")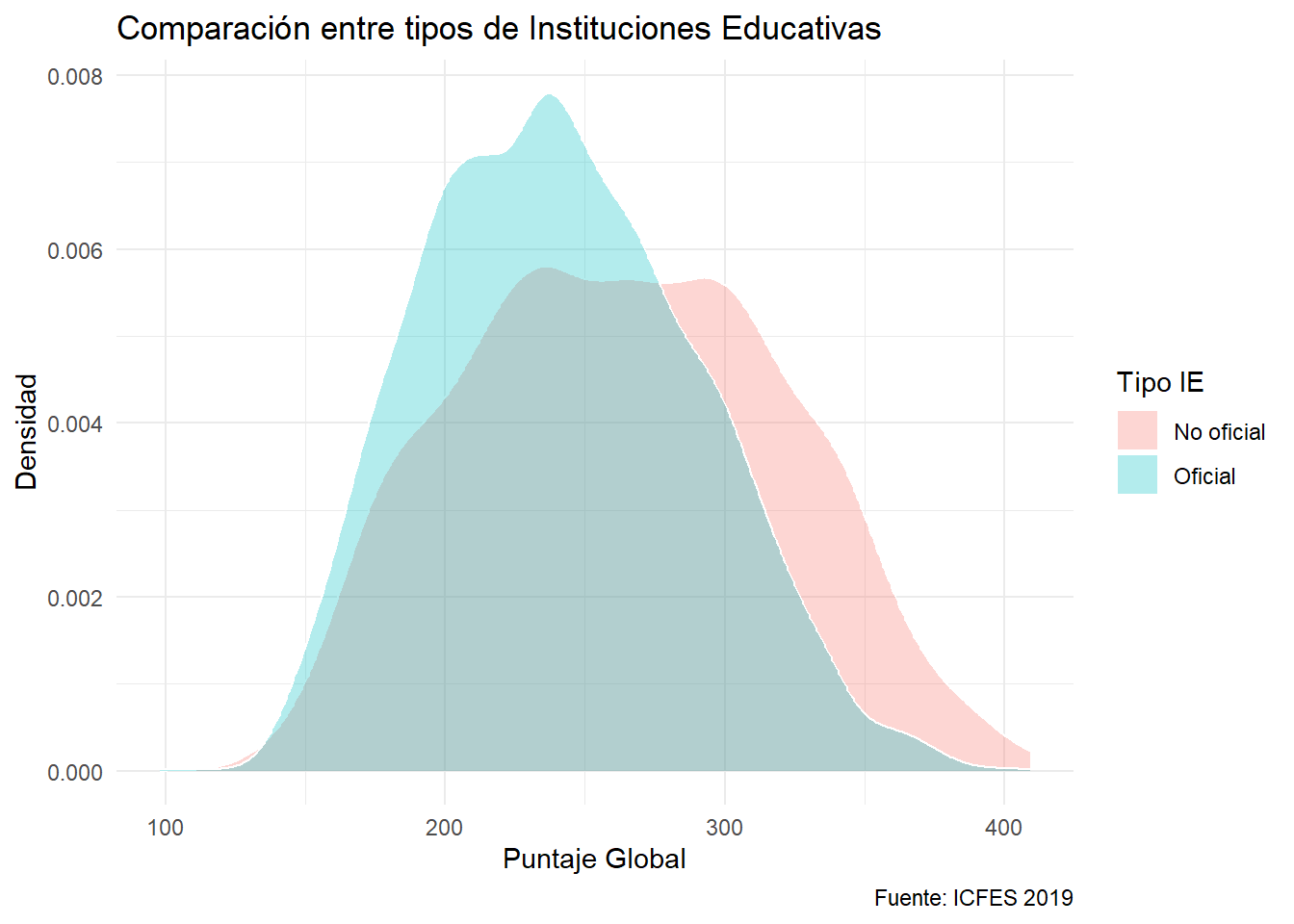
Observe que añadir una etiqueta que concuerde con la etiqueta de la estética que se utilice para categorizar, dará título a la leyenda. En el ejemplo, se utilizó el color de relleno como estética para separar por tipo de Institución Educativa. La etiqueta específico “Tipo IE” asociado a fill, el color de relleno.
Si la visualización se va a ver impresa, suele ser una opción económica no jugar con el color sino con el patrón de las líneas:
ggplot(saber) +
aes(x=punt_global,linetype = estu_genero) +
geom_density() +
labs(title = "Comparación según sexo",
x = "Puntaje Global",
y = "Densidad",
caption = "Fuente: ICFES 2019",
linetype = "Sexo")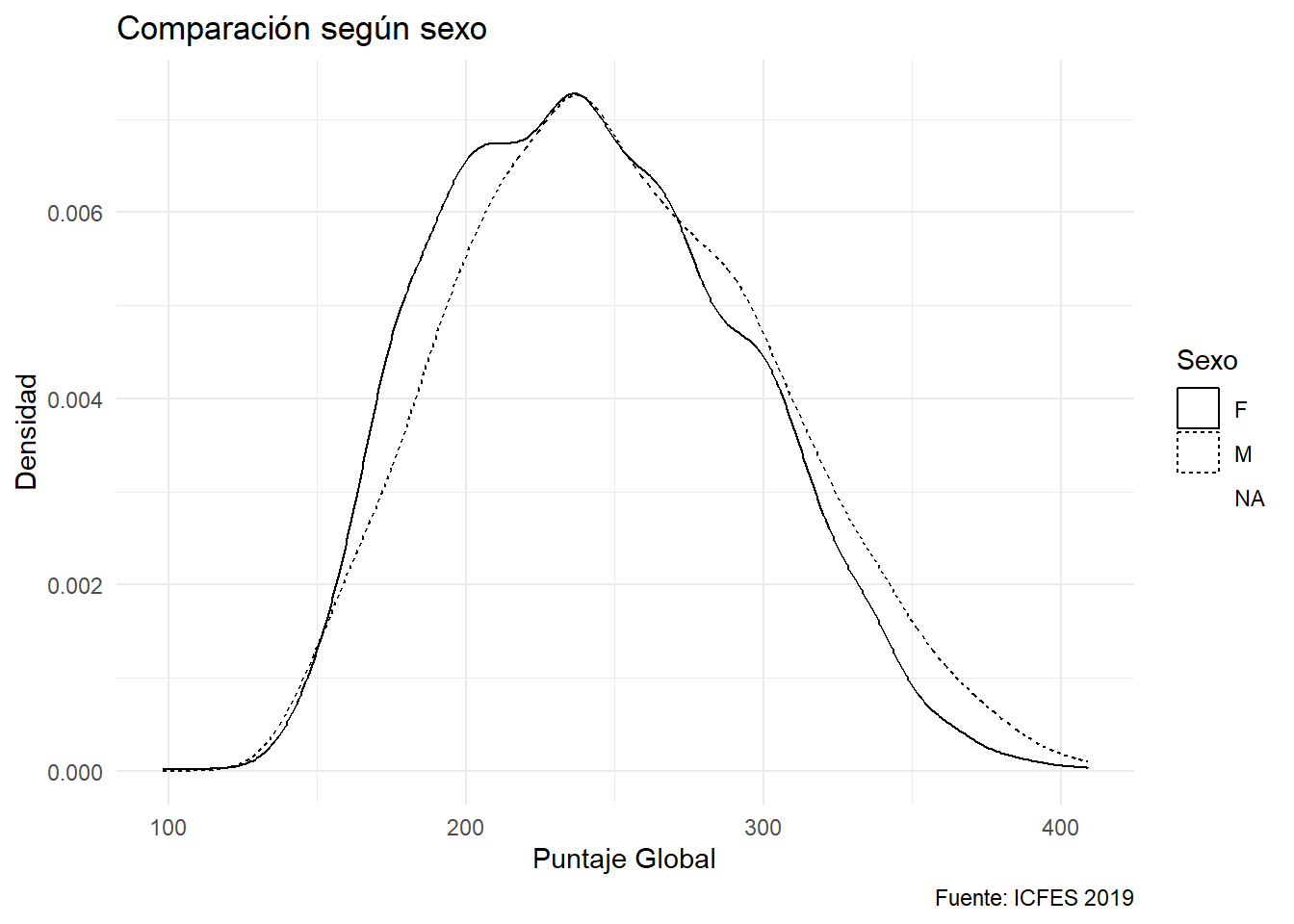
Observe las opciones de la leyenda. Hay valores faltantes. No debe figurar dicha opción. Y puede no ser evidente para todo el público el significado de F y M. Se puede mejorar con una capa (scale_linetype_discrete):
ggplot(saber) +
aes(x=punt_global,linetype = estu_genero) +
geom_density() +
labs(title = "Comparación según sexo",
x = "Puntaje Global",
y = "Densidad",
caption = "Fuente: ICFES 2019",
linetype = "Sexo") +
scale_linetype_discrete(na.translate = FALSE,
labels = c("Femenino", "Masculino"))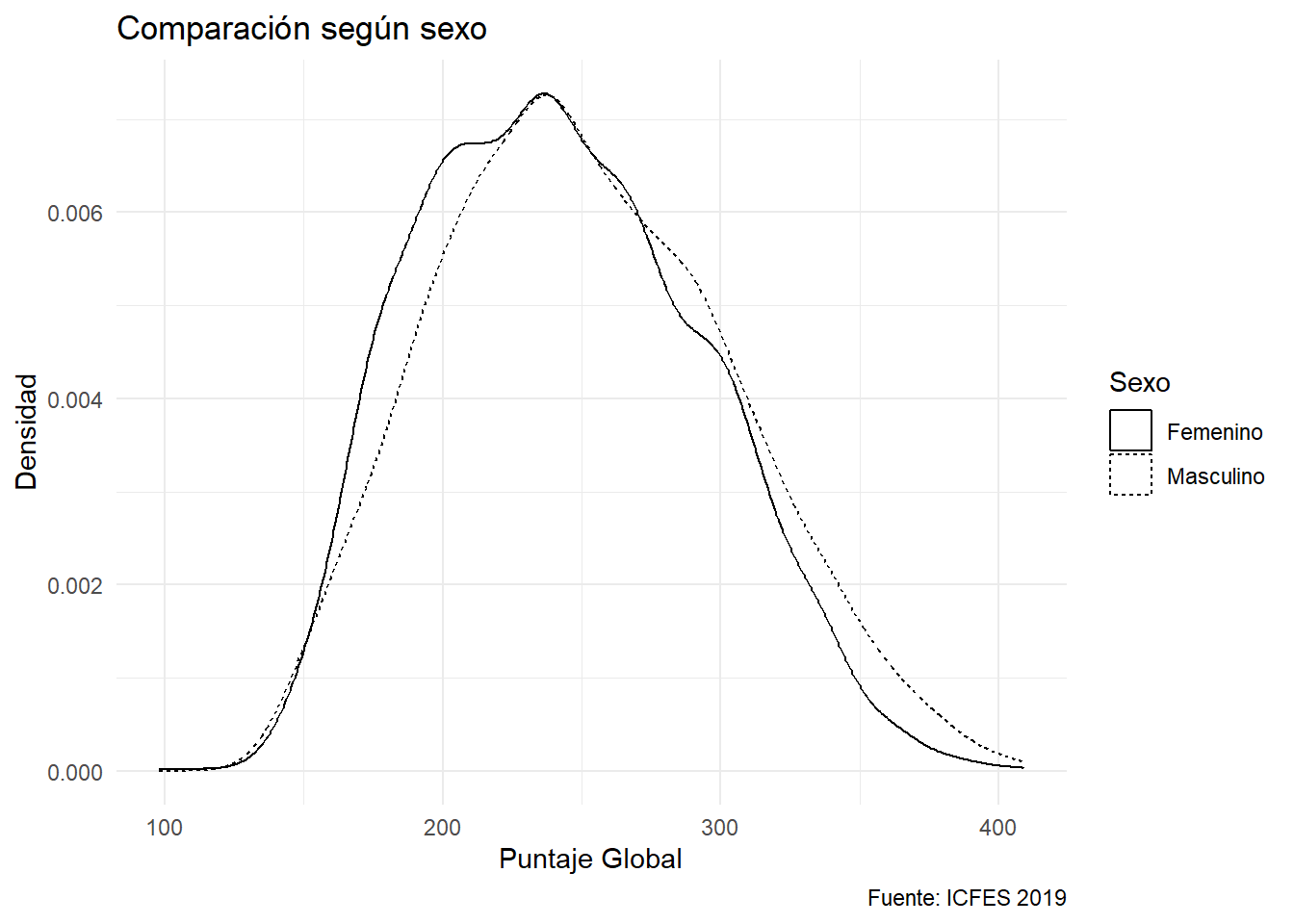
La capa especifica que se asignarán opciones a la línea que se usó para categorizar. Se añaden los nombres de cada opción y se añade na.translate = FALSE que indica que no se presenten los NA. Pero es mejor opción aún no haberlos incorporado en la visualización. Se filtra la data:
ggplot(saber %>% filter(!is.na(estu_genero))) +
aes(x=punt_global,linetype = estu_genero) +
geom_density() +
labs(title = "Comparación según sexo",
x = "Puntaje Global",
y = "Densidad",
caption = "Fuente: ICFES 2019",
linetype = "Sexo") +
scale_linetype_discrete(labels = c("Femenino", "Masculino"))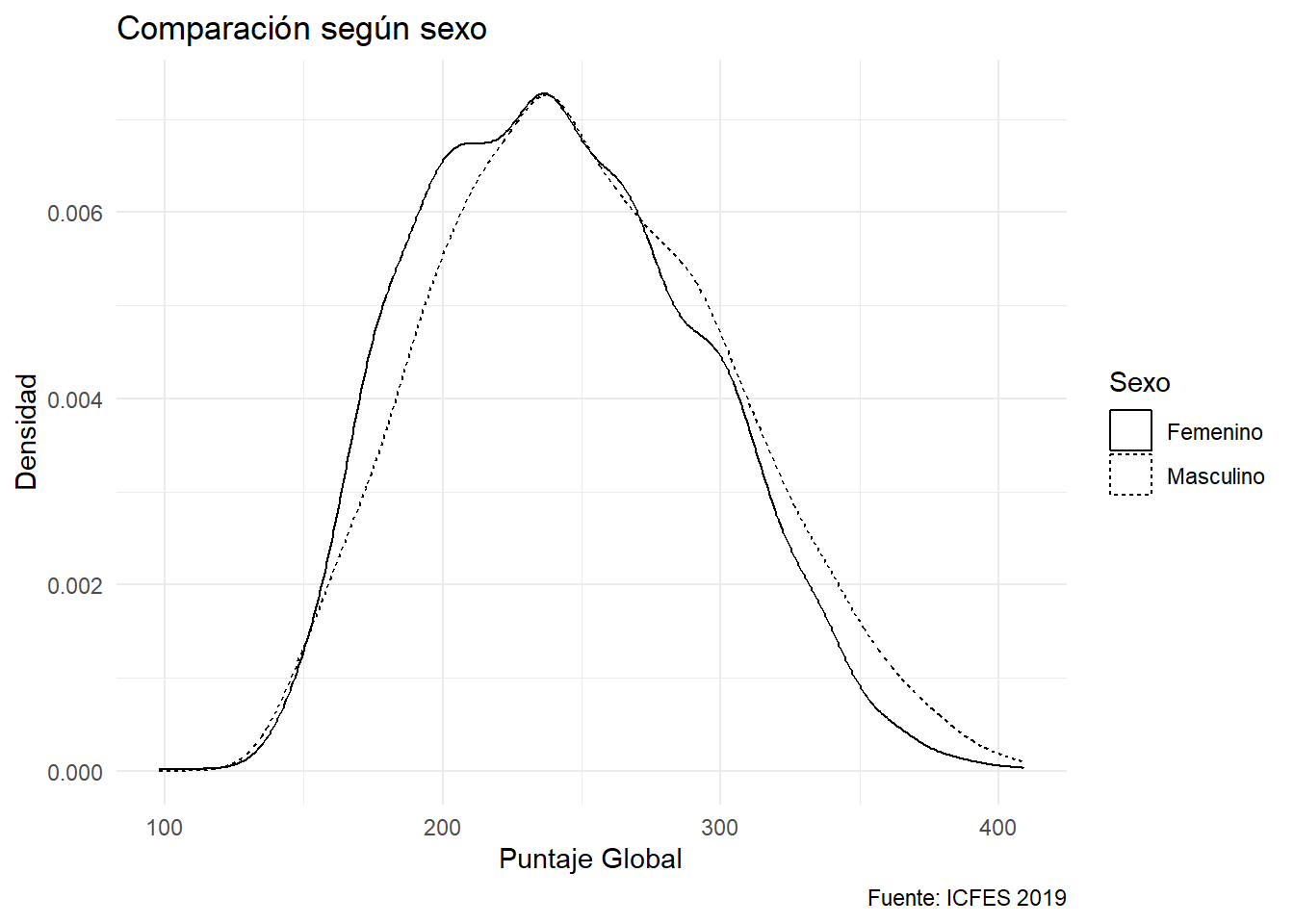
Ver la hoja de referencia de ggplot2. O ver la siguiente viñeta: