17.5 Las barras de error
Son una herramienta que se utiliza en visualización para presentar la variabilidad de los datos. Se debe entender que se trata de datos numéricos. Recuérdese que el inverso de la variabilidad es la precisión, así que también se puede utilizar para presentar la precisión de los datos.
Las barras de error pueden presentar diferentes estadísticos:
- La desviación estándar (DS)
- El intervalo de confianza (IC)
- El error estándar (EE)
- El rango.
Para el ejemplo, se utiliza una base de datos creada por la Universidad de California, Irvine (UCI) que se utiliza para evaluar la eficiencia energética de edificios. Los investigadores crearon diferentes simulaciones de 12 tipos de edificios con variaciones en su superficie acristalada, distribución y orientación, entre otros factores, lo que resultó en 768 formas de edificios. La base de datos contiene 8 características y 2 respuestas de valor real, lo que significa que se pueden utilizar para predecir cómo funcionará un edificio en términos de calefacción y refrigeración. La base de datos es útil para investigadores y profesionales que quieren mejorar la eficiencia energética de los edificios y puede ser utilizada en una variedad de aplicaciones.
Son en total 1296 registros, lo cual hace que el error estándar sea muy pequeño.
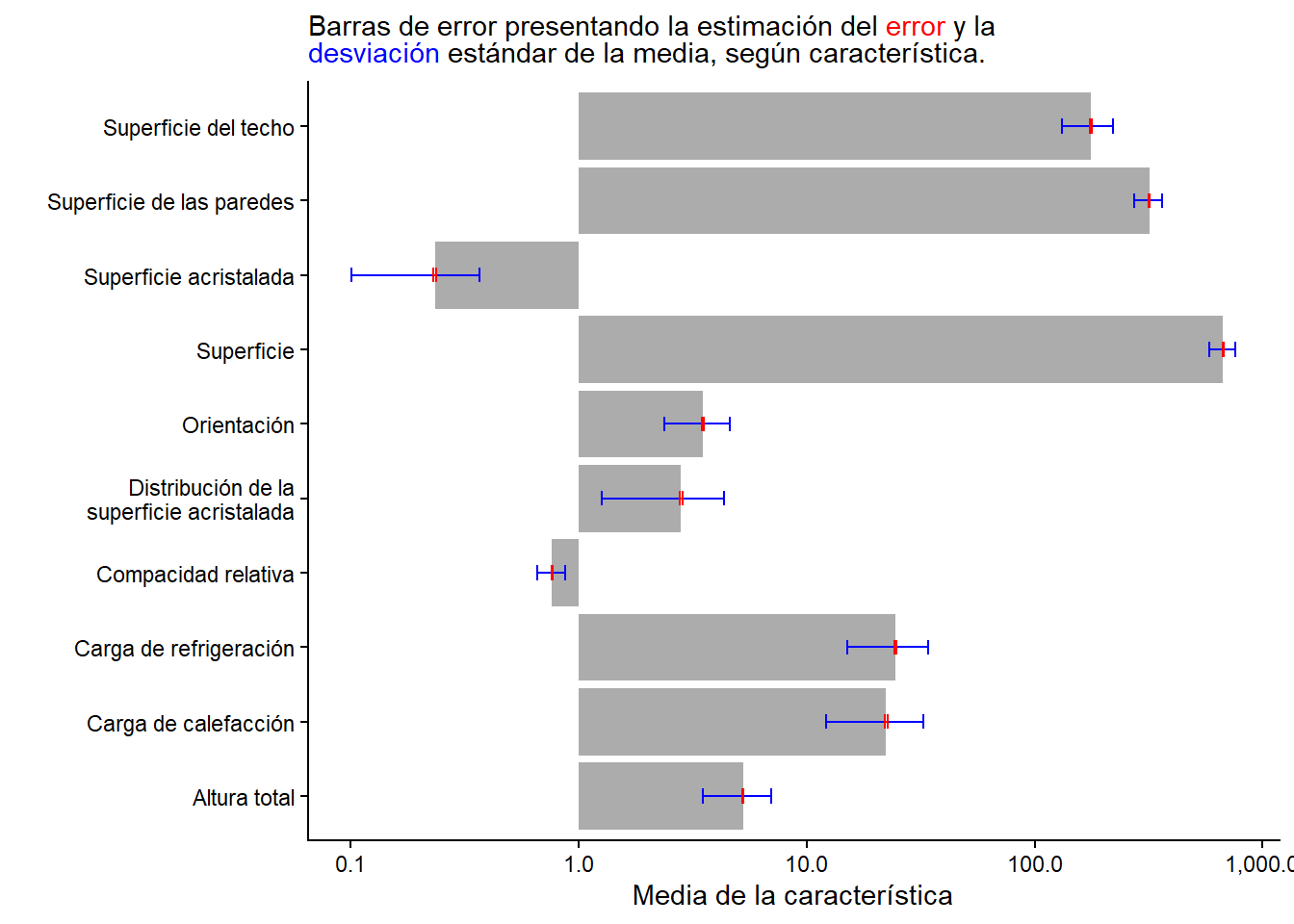
Obsérvese que la escala logarítmica del eje x provoca que el bigote izquierdo de la desviación estándar es más largo que el derecho y que las barras crecen a partir del valor 1. También obsérvese que es imperceptible la barra del error estándar debido al gran tamaño de la base de datos.
Lo usual es presentar estos estadísticos para varias categorías con el objeto de permitir una comparación.
En general es aconsejable evitar la mezcla de barras y barras de error ya que los usuarios tienden a mal interpretarlas. Dustin Fife(Fife 2022) cita a Correll(Correll 2015): “Cuando las medias y los errores estándar se presentan en forma de gráficos de barras, las personas tienden a considerar que los valores por debajo de la media (es decir, dentro de los límites de la barra) son mucho más probables que los valores por encima de la media, incluso cuando la distribución subyacente es simétrica.”
Los histogramas, diagramas de densidad y diagramas de caja y bigotes están diseñados para presentar las estadísticas de resumen y la distribución de probabilidad de variables numéricas continuas. Si se añaden los puntos con perturbaciones aleatorias (jittered dots) o indicadores de ubicaciones de los datos por medio del diagrama de flecos (rug plot) mucho mejor.
Para comparar intervalos de confianza, desviaciones estándar o errores estándar, es mejor utilizar líneas (Ver capítulo de Presentando la distribución de los datos).
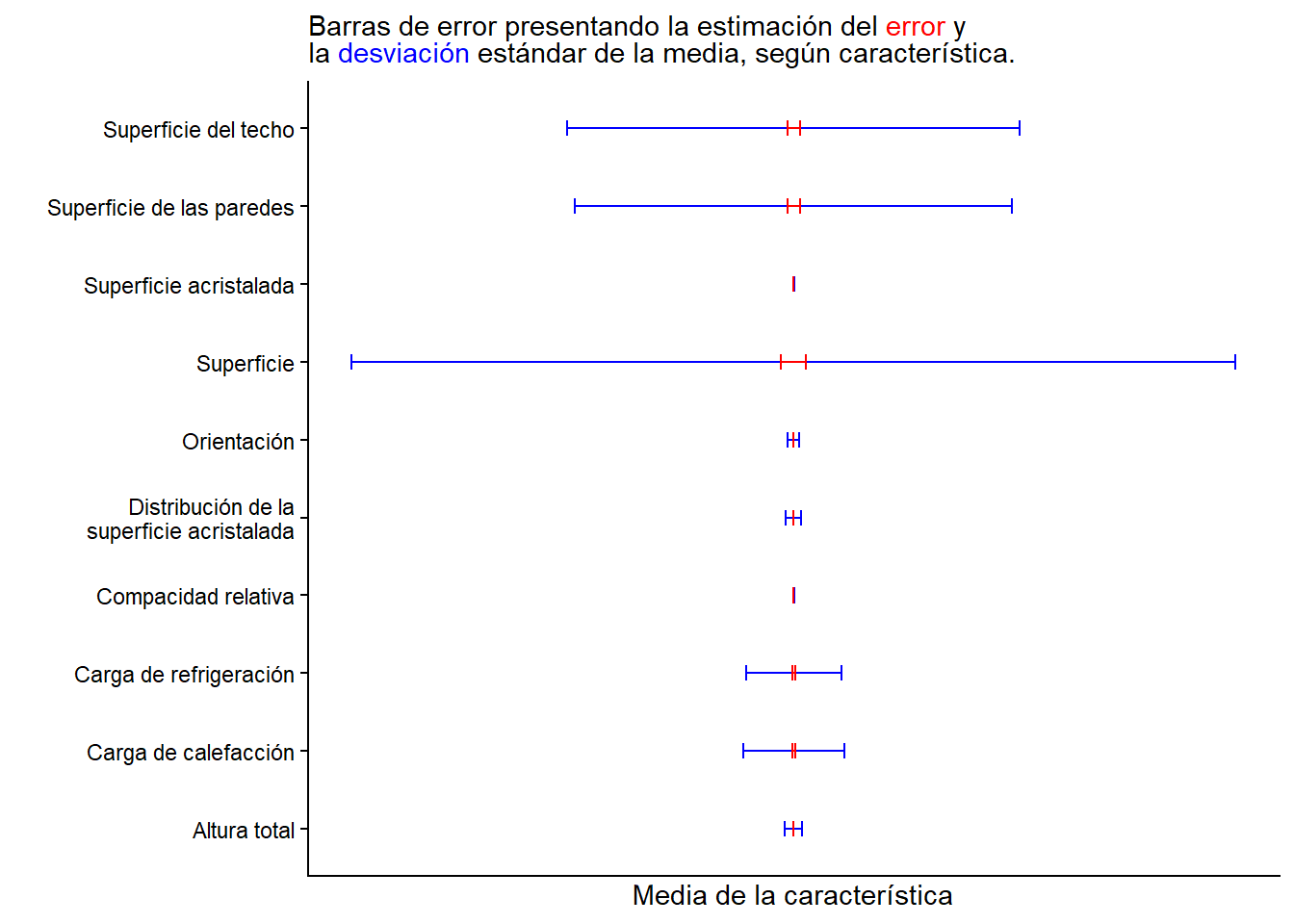
- Las barras de error no representan la precisión absoluta de los datos, sino una estimación del margen de error o incertidumbre asociado con el valor numérico.
- Las barras de error no muestran la distribución completa de los datos, solo la variabilidad de las medidas utilizadas para calcular el promedio.
- Las barras de error pueden ser engañosas si son demasiado pequeñas o si la longitud de la barra de error elegida es incorrecta.
- Las barras de error no son adecuadas para datos no normales.
- Para entender las barras de error, la audiencia debe conocer algunos conceptos previos, por lo que no son para cualquier público.